tensorflow中如何實(shí)現(xiàn)張量的提取值和賦值-創(chuàng)新互聯(lián)
小編給大家分享一下tensorflow中如何實(shí)現(xiàn)張量的提取值和賦值,相信大部分人都還不怎么了解,因此分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后大有收獲,下面讓我們一起去了解一下吧!
創(chuàng)新互聯(lián)是一家專業(yè)提供蓮花企業(yè)網(wǎng)站建設(shè),專注與網(wǎng)站設(shè)計(jì)制作、網(wǎng)站建設(shè)、HTML5建站、小程序制作等業(yè)務(wù)。10年已為蓮花眾多企業(yè)、政府機(jī)構(gòu)等服務(wù)。創(chuàng)新互聯(lián)專業(yè)網(wǎng)絡(luò)公司優(yōu)惠進(jìn)行中。tf.gather和gather_nd從params中收集數(shù)值,tf.scatter_nd 和 tf.scatter_nd_update用updates更新某一張量。嚴(yán)格上說,tf.gather_nd和tf.scatter_nd_update互為逆操作。
已知數(shù)值的位置,從張量中提取數(shù)值:tf.gather, tf.gather_nd
tf.gather indices每個(gè)元素(標(biāo)量)是params某個(gè)axis的索引,tf.gather_nd 中indices最后一個(gè)階對(duì)應(yīng)于索引值。
tf.gather函數(shù)
函數(shù)原型
gather( params, indices, validate_indices=None, name=None, axis=0 )
params是要查找的張量,indices是要查找值的索引(int32或int64),axis是查找軸,name是操作名。
如果indices是標(biāo)量
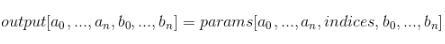
如果indices是向量

如果indices是高階張量
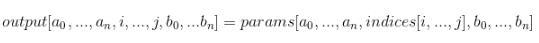
返回值:
該函數(shù)返回值類型與params相同,具體值是從params中收集過來的,形狀為
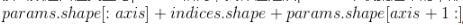
tf.gather_nd函數(shù)
函數(shù)原型
gather_nd( params, indices, name=None )
indices是K階張量,包含K-1階的索引值。它最后一階是索引,最后一階維度必須小于等于params的秩。indices最后一階的維數(shù)等于params的秩時(shí),我們得到params的某些元素;indices最后一階的維數(shù)小于params的秩時(shí),我們得到params的切片。

輸出張量的形狀由indices的K-1階和params索引到的形狀拼接而成,如下面
indices.shape[:-1] + params.shape[indices.shape[-1]:]
參數(shù):
params:被收集的張量。
indices:索引張量。必須是以下類型之一:int32,int64。
name:操作的名稱(可選)。
返回值:
該函數(shù)返回一個(gè)張量.與params具有相同的類型。張量值從indices所給定的索引中收集,并且具有這樣的形狀:

已知賦值的位置,向張量賦值:tf.scatter_nd, tf.scatter_nd_update
tf.scatter_nd對(duì)零張量進(jìn)行賦值,tf.scatter_nd_update對(duì)已有可變的張量進(jìn)行賦值。
tf.scatter_nd函數(shù) scatter_nd( indices, updates, shape, name=None )
創(chuàng)建一個(gè)形狀為shape的零張量,將updates賦值到indices指定的位置。
indices是整數(shù)張量,最內(nèi)部維度對(duì)應(yīng)于索引。
indices.shape[-1] <= shape.rank
如果indices.shape[-1] = shape.rank,那么indices直接對(duì)應(yīng)到新張量的單個(gè)元素。如果indices.shape[-1] < shape.rank,那么indices中每個(gè)元素對(duì)新張量做切片操作。updates的形狀應(yīng)該如下所示
indices.shape[:-1] + shape[indices.shape[-1]:]
如果我們要把形狀為(4,)的updates賦值給形狀為(8,)的零張量,如下圖所示。

我們需要這樣子做
indices = tf.constant([[4], [3], [1], [7]]) updates = tf.constant([9, 10, 11, 12]) shape = tf.constant([8]) scatter = tf.scatter_nd(indices, updates, shape) with tf.Session() as sess: print(sess.run(scatter))
我們得到這樣子的張量
[0, 11, 0, 10, 9, 0, 0, 12]
上面代碼中,indices的形狀是(4,1),updates的形狀是(4,),shape的形狀是(8,)。
indices.shape[:-1]+shape[indices.shape[-1]:] = (4,)+(,)=(4,)
如果我們要在三階張量中插入兩個(gè)切片,如下圖所示,則應(yīng)該像下面代碼里所說的那樣子做。

indices = tf.constant([[0], [2]]) updates = tf.constant([[[5, 5, 5, 5], [6, 6, 6, 6], [7, 7, 7, 7], [8, 8, 8, 8]], [[5, 5, 5, 5], [6, 6, 6, 6], [7, 7, 7, 7], [8, 8, 8, 8]]]) shape = tf.constant([4, 4, 4]) scatter = tf.scatter_nd(indices, updates, shape) with tf.Session() as sess: print(sess.run(scatter))
indices的形狀是(2,1),updates的形狀是(2,4,4),shape的形狀是(4,4,4)。
indices.shape[:-1]+shape[indices.shape[-1]:]=(2,)+(4,4)=(2,4,4)
我們會(huì)得到這樣子的張量
[[[5, 5, 5, 5], [6, 6, 6, 6], [7, 7, 7, 7], [8, 8, 8, 8]], [[0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0]], [[5, 5, 5, 5], [6, 6, 6, 6], [7, 7, 7, 7], [8, 8, 8, 8]], [[0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0]]]
函數(shù)參數(shù)
indices:Tensor;必須是以下類型之一:int32,int64;索引值張量。
updates:Tensor;分散到輸出的更新。
shape:Tensor;必須與indices具有相同的類型;1-d;得到的張量的形狀。
name:操作的名稱(可選)。
返回值
此函數(shù)返回一個(gè)Tensor,它與updates有相同的類型;一個(gè)有shape形狀的新張量,初始化值為0,部分值根據(jù)indices用updates進(jìn)行更新。
tf.scatter_nd_update函數(shù)
函數(shù)原型
scatter_nd_update( ref, indices, updates, use_locking=True, name=None )
scatter_nd_update也是把updates里面的值根據(jù)indices賦值到另外一個(gè)張量中,與scatter_nd不同的是,它是賦值到ref。
ref是秩為P的張量,indices是秩為Q的張量。
indices是整數(shù)類型的張量,必須具有這樣的形狀 。
。
indices最內(nèi)部的維度對(duì)應(yīng)于ref的某個(gè)元素或切片。
updates的形狀是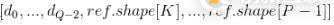 ,是秩為Q-1+P-K的張量。
,是秩為Q-1+P-K的張量。
如果我們想要把(4,)的向量賦值到(8,)的ref中,我們可以像下面這樣子操作。
ref = tf.Variable([1, 2, 3, 4, 5, 6, 7, 8]) indices = tf.constant([[4], [3], [1] ,[7]]) updates = tf.constant([9, 10, 11, 12]) update = tf.scatter_nd_update(ref, indices, updates) with tf.Session() as sess: print sess.run(update)
我們可以得到這樣的ref
[1, 11, 3, 10, 9, 6, 7, 12]
函數(shù)參數(shù)
ref:一個(gè)可變的Tensor。
indices:一個(gè) int32 或 int64 Tensor;一個(gè)對(duì)ref進(jìn)行索引的張量.
updates:一個(gè)Tensor.必須與ref具有相同的類型;更新值張量.
use_locking:可選的bool;如果為True,則賦值將受鎖定的保護(hù);否則行為是不確定的,但可能表現(xiàn)出較少的爭(zhēng)用.
name:操作的名稱(可選).
返回值:
經(jīng)過更新的ref。
以上是“tensorflow中如何實(shí)現(xiàn)張量的提取值和賦值”這篇文章的所有內(nèi)容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內(nèi)容對(duì)大家有所幫助,如果還想學(xué)習(xí)更多知識(shí),歡迎關(guān)注創(chuàng)新互聯(lián)行業(yè)資訊頻道!
文章名稱:tensorflow中如何實(shí)現(xiàn)張量的提取值和賦值-創(chuàng)新互聯(lián)
地址分享:http://m.kartarina.com/article40/ccigho.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供移動(dòng)網(wǎng)站建設(shè)、用戶體驗(yàn)、網(wǎng)站設(shè)計(jì)、微信小程序、App開發(fā)、動(dòng)態(tài)網(wǎng)站
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請(qǐng)盡快告知,我們將會(huì)在第一時(shí)間刪除。文章觀點(diǎn)不代表本網(wǎng)站立場(chǎng),如需處理請(qǐng)聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時(shí)需注明來源: 創(chuàng)新互聯(lián)
猜你還喜歡下面的內(nèi)容
- 服務(wù)部署遇到的一些小問題-創(chuàng)新互聯(lián)
- 利用php怎么將網(wǎng)絡(luò)圖片保存到服務(wù)器中-創(chuàng)新互聯(lián)
- 怎么在cmd命令窗口中搭建一個(gè)python開發(fā)環(huán)境-創(chuàng)新互聯(lián)
- wms用地性質(zhì)M是什么意思?-創(chuàng)新互聯(lián)
- 寫批處理必備的命令參數(shù)使用技巧有哪些-創(chuàng)新互聯(lián)
- 什么是Scheme?原來還可以這樣應(yīng)用!-創(chuàng)新互聯(lián)
- Python中如何獲取高考志愿信息-創(chuàng)新互聯(lián)

- 網(wǎng)站制作不能忽視百度點(diǎn)評(píng) 2021-12-13
- 網(wǎng)站制作淺析網(wǎng)站建設(shè)必備的三大條件 2016-08-08
- 網(wǎng)站制作與建設(shè)怎么才能打開的更快 2023-03-06
- 成都seo優(yōu)化中網(wǎng)站排名不穩(wěn)定的原因? 2016-12-29
- 網(wǎng)站制作淺談付費(fèi)的搜索引擎推廣 2021-09-04
- 網(wǎng)站制作前期準(zhǔn)備工作是那些你有提前準(zhǔn)備嗎? 2016-10-25
- 時(shí)間就是金錢 網(wǎng)站制作過程中客戶務(wù)必要做好對(duì)接配合工作 2022-05-19
- 博物館網(wǎng)站制作 網(wǎng)頁設(shè)計(jì)都有哪些流程 2022-05-02
- 廣州網(wǎng)站制作備案需要多長(zhǎng)時(shí)間? 2022-12-10
- 成都網(wǎng)站制作的字體排版 2016-08-24
- 一般網(wǎng)站制作收費(fèi)標(biāo)準(zhǔn),你想了解嗎? 2023-03-13
- 成都網(wǎng)站制作標(biāo)準(zhǔn)化的意義 2016-10-31