Python中如何獲取高考志愿信息-創新互聯
這篇文章給大家分享的是有關Python中如何獲取高考志愿信息的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
創新互聯公司是一家專業提供新區企業網站建設,專注與成都網站制作、成都做網站、成都h5網站建設、小程序制作等業務。10年已為新區眾多企業、政府機構等服務。創新互聯專業網絡公司優惠進行中。準備工作
首先明確一下任務。首先我們要從網址表格中讀取到一大串網址,然后訪問每個網址,獲取到頁面上的學校信息,然后將它們在寫到另一個Excel中。顯然,我們需要一個爬蟲庫和一個Excel庫來幫助我們完成任務。
第一步自然是安裝它們,requests-html是一個非常好用的HTML解析庫,拿來做簡單的爬蟲非常優雅;而openpyxl是一個Excel表格庫,可以輕松創建和處理Excel數據。
pip install requests-html openpyxl
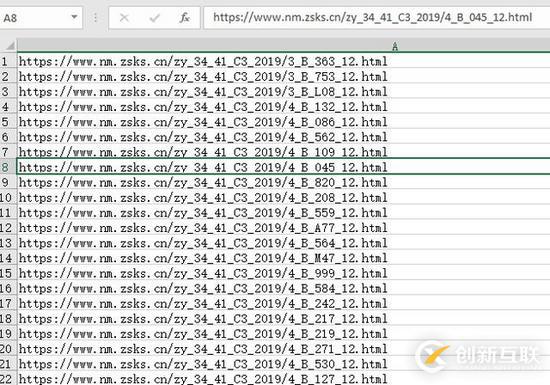
然后就是網址表格,大概長這樣,總共大概一千七百多條數據。其中有少量網址是錯誤的,訪問會得到404錯誤,所以在編寫代碼的時候還要注意錯誤處理。
任務分析
任務的核心自然就是分析和獲取網頁內容了。首先現在瀏覽器里面打開一個網址,看看網頁上的內容是什么。
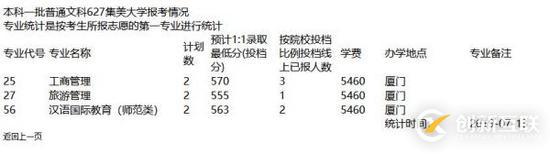
可以看到這個網頁格式很亂,學校名字什么的都是混在一起的,一點也不規整,這給我們提取數據造成了不少的麻煩。不過仔細分析之后,其實問題也并不難。
首先要提取的是學校名字,可以看到學校名字和其他文字混在一起,例如"本科一批普通文科627集美大學報考情況"。本來我準備用正則表達式提取,然后發現用正則表達式好像很難。之后我多訪問了幾個網頁,發現學校代碼基本上都是數字,如果有字母的話也出現到第一位,所以我采用了以下的算法,首先將字符串從數字處分隔,右邊的一個部分就包含了學校名字和“報考情況”幾個字,然后刪除“報考情況”即可得到學校名字。這個算法唯一的缺點就是,假如出現了字母在中間的代號,就沒辦法獲取到學校名字了,不過實際運行之后,我幸運的發現并沒有出現這種情況。
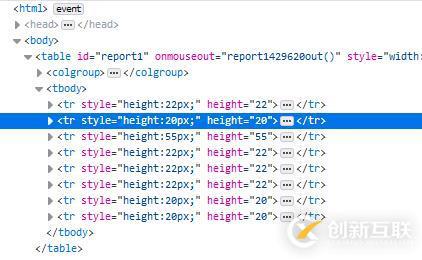
之后要提取的就是專業信息了,在網頁源代碼中這部分使用tr和td標簽來呈現的。一開始我用的是tr加上選擇器來提取,但是這個網頁生成的時候很有問題,每個tr標簽的樣式居然還根據內容的多少而不同,導致我寫死的選擇器沒法完美獲取所有行。不過后來我發現整個網頁內容都是一個表格, 除去表頭和結尾的幾個固定行之外,剩下的恰好就是要提取的數據行,所以直接獲取tr標簽,然后切片除去收尾即可。
網頁基本上分析完了,下面就是編寫代碼了。
編寫代碼
總共50行左右代碼,我添加了注釋,相信大家應該很容易就可以看懂。
第一部分代碼是從網址表格讀取所有url,一開始編寫的時候,表格里的url是從另一個公式生成的,所以需要在加載的時候添加data_only=True才能讀取到公式的結果,否則只能讀取到公式本身。
第二部分是創建輸出文件,然后編寫表頭。順帶為了調試方便,我讓它如果檢測到已經存在目標文件的話就刪掉,在建立一個新的。
第三部分就是代碼的核心了。Python代碼看著可能有點奇怪,不過對照上面的分析,我想大家應該很容易看懂。需要注意保存文件在最后,假如半路代碼出現異常,整個就白干了,而一千七百多條網址不可能保證都正常運行。由于輸出格式是“學校名+專業信息”這樣的格式,所以我獲取學校名之后,還要將學校插入到每行專業信息之前。所以我這里索性直接用try-except包起來,如果出錯的話只打印一下出錯的網址。
import os
from requests_html import HTMLSession
from openpyxl import Workbook, load_workbook
# 從網址表格獲取urls
def get_urls():
input_file = 'source.xlsx'
wb = load_workbook(input_file, data_only=True)
ws = wb.active
urls = [row[0] for row in ws.values]
wb.close()
return urls
# 輸出Excel文件,如果已存在則刪除已有的
out_file = 'data.xlsx'
if os.path.exists(out_file):
os.remove(out_file)
wb = Workbook()
ws = wb.active
# 編寫第一行表頭
ws['a1'] = '學校'
ws['b1'] = '專業代號'
ws['c1'] = '專業名稱'
ws['d1'] = '計劃數'
ws['e1'] = '預計1:1錄取最低分(投檔分)'
ws['f1'] = '按院校投檔比例投檔線上已報人數'
ws['g1'] = '學費'
ws['h2'] = '辦學地點'
ws['i1'] = '專業備注'
# 發起網絡請求,解析網頁信息,并寫入文件
session = HTMLSession()
urls = get_urls()
for url in urls:
import re
page = session.get(url)
page.html.encoding = 'gb2312'
try:
college_info = page.html.xpath('//td[@class="report1_1_1"]/text()', first=True)
college = re.split('\d+', college_info)[1].replace('報考情況', '')
rows = page.html.xpath('//tr')[3:-2]
for r in rows:
info = [x.text for x in r.xpath('//td')]
info.insert(0, college)
ws.append(info)
print(info)
except:
print(url)
# 保存文件
wb.save(out_file)運行結果
好了,費了大半天的勁,代碼終于完成了。讓我們運行一下看看結果。整個代碼大概需要運行7-8分鐘,最后完成之后得到了一個500多k的Excel文件。
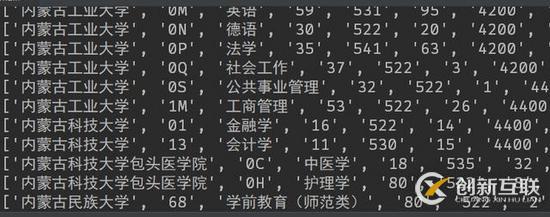
打開之后,可以發現Excel文件填的滿滿的,最后總共獲取到了大約一萬多條數據,任務圓滿完成。
python的五大特點是什么
python的五大特點:1.簡單易學,開發程序時,專注的是解決問題,而不是搞明白語言本身。2.面向對象,與其他主要的語言如C++和Java相比, Python以一種非常強大又簡單的方式實現面向對象編程。3.可移植性,Python程序無需修改就可以在各種平臺上運行。4.解釋性,Python語言寫的程序不需要編譯成二進制代碼,可以直接從源代碼運行程序。5.開源,Python是 FLOSS(自由/開放源碼軟件)之一。
感謝各位的閱讀!關于“Python中如何獲取高考志愿信息”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
另外有需要云服務器可以了解下創新互聯scvps.cn,海內外云服務器15元起步,三天無理由+7*72小時售后在線,公司持有idc許可證,提供“云服務器、裸金屬服務器、高防服務器、香港服務器、美國服務器、虛擬主機、免備案服務器”等云主機租用服務以及企業上云的綜合解決方案,具有“安全穩定、簡單易用、服務可用性高、性價比高”等特點與優勢,專為企業上云打造定制,能夠滿足用戶豐富、多元化的應用場景需求。
分享名稱:Python中如何獲取高考志愿信息-創新互聯
文章源于:http://m.kartarina.com/article26/ccigjg.html
成都網站建設公司_創新互聯,為您提供網站收錄、服務器托管、云服務器、用戶體驗、網站排名、網站改版
聲明:本網站發布的內容(圖片、視頻和文字)以用戶投稿、用戶轉載內容為主,如果涉及侵權請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網站立場,如需處理請聯系客服。電話:028-86922220;郵箱:631063699@qq.com。內容未經允許不得轉載,或轉載時需注明來源: 創新互聯

- 一款APP開發需要多少時間 2022-11-16
- 怎么判斷廣州網站開發公司哪家好? 2022-12-17
- seo編輯更新文章可以用哪些小竅門? 2015-04-21
- 品牌網站定制的龍門,創新互聯一躍而過 2023-03-28
- 閻良網站建設費用:影響中小企業網站打開速度的因素有哪些? 2023-03-08
- 上海網站設計配色是很重要的 2020-11-10
- 成都網站建設必備五個交互設計技能 2023-10-30
- 桂林網站優化談談怎么交換友鏈 2023-03-13
- 設計高端網頁的7個技巧 2022-10-18
- 匯總合格的SEO人員軟文標題編寫的核心要點 2023-04-04
- 4個社會化媒體營銷策略 2022-12-26
- 服務器租用挑選機柜必須注意的四個方面 2022-10-09