數(shù)據(jù)分析:Hive、Pig和Impala
本文主要分享Hadoop三大分析工具:Hive、Pig和Impala。
目前成都創(chuàng)新互聯(lián)已為千余家的企業(yè)提供了網站建設、域名、網站空間、網站托管運營、企業(yè)網站設計、丹寨網站維護等服務,公司將堅持客戶導向、應用為本的策略,正道將秉承"和諧、參與、激情"的文化,與客戶和合作伙伴齊心協(xié)力一起成長,共同發(fā)展。
Hive和Pig是高級數(shù)據(jù)語言,基于Mapreduce,底層處理的時候會轉換成Mapreduce去提交,Hive和Pig都是開源的,Hive最初由Facebook開發(fā),Pig最初由Yahoo!開發(fā),下面進行分別介紹:
一、什么是Hive?
Hive可以看做是SQL到Mapreduce的一個映射器,就是不用開發(fā)Mapreduce,只要懂SQL就可以了,HiveQL是標準SQL92的一個子集,和標準的SQL并不完全一樣,HiveQL本身有百分之二十的一個擴展,大概百分之八十的語法和標準的SQL是一致的,像

這種標準的SQL是支持的,所以對于數(shù)據(jù)分析人員來講,就可以很方便的切入到Hadoop的平臺上去做數(shù)據(jù)分析。
二、什么是Pig?
Pig是處理大數(shù)據(jù)集的數(shù)據(jù)流語言。什么是數(shù)據(jù)流呢?就是處理數(shù)據(jù)的流程可以一步步定義,比如第一步加載,第二步轉換,第三步再轉換,第四步存儲,可以一步步定義數(shù)據(jù)的走向,很類似我們在數(shù)據(jù)挖掘中進行的系列處理流程。因為pig是數(shù)據(jù)流的語言,所以很適合做物質的數(shù)據(jù)探索和ETL階段數(shù)據(jù)的非處理,他和Spark的思想很相似,所以也可以說Spark是實現(xiàn)正確的Pig。為什么這樣說?因為Pig和Spark都是數(shù)據(jù)流似的處理,pig有轉換,行動操作,在spark里面也是一樣。
Pig數(shù)據(jù)流語言

Pig在ETL階段還是用的很多的,而且對于一些數(shù)據(jù)挖掘人員來說,尤其是探知一些未知數(shù)據(jù),非常合適。因為不需要指定任何的名稱、類型就可以先加載,然后去匹配所有的數(shù)據(jù),接下來就可以去觀察數(shù)據(jù)是怎樣的,分析怎么去做轉換。Pig是一種語義很精準的語言,所以學起來也會很方便的。
hive與pig的對比

三、什么是Impala?
盡管我們有了hive,但是hive是基于mapreduce,它的分析效率并不高,大家都著力去找到一種高性能的SQL的引擎,impala的出現(xiàn)就解決了這一問題。Impala是處理海量數(shù)據(jù)的高性能SQL引擎,它的查詢可以達到秒及,甚至有些數(shù)據(jù)少的可以達到毫秒級,延遲很低,比Hive、Pig或MapReduce快10到50倍,它的SQL 也是類似于HiveQL的查詢語言,他和標準的SQL也是有百分之八十的語法重復,也有自己的擴展一部分。Impala它使用的數(shù)據(jù)是和Hive一樣的,就好比在Hive里面創(chuàng)建一個表,Impala也是可以訪問的,反之也是一樣的。Impala運行在Hadoop集群上,數(shù)據(jù)存儲在HDFS,不能使用MapReduce,他有自己的架構,也是主存的結構,每一個服務可以直接對數(shù)據(jù)塊進行訪問。Impala由Cloudera開發(fā),100%開源,在Apache軟件許可下發(fā)布。
那么有三種數(shù)據(jù)分析方案,在實際操作中,我們怎樣來使用呢?總體來講Pig沒有Hive和Impala用的多,可是他們各有優(yōu)勢。接下來描述一下他們各自的使用條件:我們知道Impala是近實時的查詢,使用數(shù)據(jù)和Hive一樣,那么我們就會去問,為什么還要使用Hive呢?有一些復雜的文本分析只能用Hive,比如一些CSV的文件,一些高頻詞的分析,統(tǒng)計分析只能用Hive,Impala不支持.還有一些復雜類型的使用,比如用到數(shù)組,復雜的結構體這些也都只能用Hive。Impala主要用于及時的,交互式的分析,Hive用于穩(wěn)定性挖掘比較高,實時性挖掘不高的作業(yè)。Pig也可以支持一些復雜的類型,但是pig沒有固定的模型,如果做一些做臨時的數(shù)據(jù)探索可以用。
比較Hive、Pig和Impala
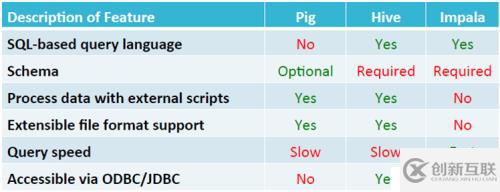
那么他們可以替代RDBMS嗎?當然不行,關系型數(shù)據(jù)支持事務,延遲低,隨時可以修改,而Hive和Impala做不到,所以代替不了關系型數(shù)據(jù)庫,Pig、Hive和Impala主要適用于大量數(shù)據(jù)讀以及低成本的廣泛擴展。
分析工作流示意

以上就是筆者根據(jù)自己的知識體系給大家分享的數(shù)據(jù)分析內容,主要是針對Hive、Pig和Impala各自的特點、應用、區(qū)分,以及與傳統(tǒng)數(shù)據(jù)庫的區(qū)別來進行闡述,對于深入了解數(shù)據(jù)分析工具在實際中的運用有著重要作用。我在實際工作和學習中喜歡關注一些大數(shù)據(jù)實時資訊,如“大數(shù)據(jù)cn”,對于了解和把握大數(shù)據(jù)的發(fā)展狀況有著很大作用,而且也喜歡去看一些別人分享的知識架構,比如“大數(shù)據(jù)時代學習中心”,來不斷豐富和完善自己的知識體系,這些都極大促進了我的發(fā)展,推薦給大家。
分享題目:數(shù)據(jù)分析:Hive、Pig和Impala
鏈接分享:http://m.kartarina.com/article8/jedhip.html
成都網站建設公司_創(chuàng)新互聯(lián),為您提供網站營銷、品牌網站設計、ChatGPT、微信公眾號、網頁設計公司、營銷型網站建設
聲明:本網站發(fā)布的內容(圖片、視頻和文字)以用戶投稿、用戶轉載內容為主,如果涉及侵權請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網站立場,如需處理請聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內容未經允許不得轉載,或轉載時需注明來源: 創(chuàng)新互聯(lián)

- 自助外貿建站不等于企業(yè)網站建設 2016-03-19
- 外貿建站選美國空間還是香港空間好? 2022-10-10
- 做外貿建站為什么要選穩(wěn)定快速安全的海外主機? 2015-04-29
- 外貿建站不得不說的秘密 2015-05-07
- 外貿建站之營銷型網站 2016-03-26
- 外貿建站租用香港云服務器還是美國云服務器好? 2022-10-02
- 外貿建站和普通網站建設的區(qū)別 2022-10-22
- 外貿建站完成后如何繼續(xù)完善 2021-08-25
- 外貿建站推廣?八大技巧幫您引流 2016-03-01
- 為什么要選擇外貿建站? 2015-04-27
- 按外貿建站域名五原則挑選老外喜歡的域名 2015-05-01
- 外貿建站要關注的一些問題 2023-03-05