memcache緩存服務器是什么?-創新互聯
1,memcache簡介
mamcache是一套分布式的高速緩存系統,可以提高網站訪問的速度,尤其是對于一些大型的公司或者頻繁訪問數據庫的網站訪問速度提升效果十分顯著,memcache是一個開源免費的軟件,memcache通過鍵值對的訪問將數據緩存在內存當中,減少從后端數據讀取數據的次數。
成都創新互聯公司從2013年成立,是專業互聯網技術服務公司,擁有項目做網站、網站設計網站策劃,項目實施與項目整合能力。我們以讓每一個夢想脫穎而出為使命,1280元澠池做網站,已為上家服務,為澠池各地企業和個人服務,聯系電話:135182197922,memcache分布式緩存系統
分布式:將數據分散存儲在不同服務器上。
緩存系統:嚴格意義上來說,memcache不是一個nosql數據庫,只是提供內存緩存功能系統,那怎么理解別人來說memcache是一個nosql數據庫呢?關系型數據庫是基于二維表來存放數據(事務,元祖,數據的持久性)等,最簡單的理解就是數據在斷電后不會丟失,非關系型數據庫不使用sql語句來進行數據的查詢而是基于key-value存儲和讀取數據的,所以又可以理解成nosql數據庫了。
3,memcache和mysql區別
1)沒有使用sql語句查詢或存儲數據;
2)memcache中沒有mysql的表的概念,都是使用鍵值對來保存的;
3)memcache的數據保存在內存當中,數據讀取速度快,數據斷電丟失;
4,memcache分布式部署的原理
memcache雖然被稱為“分布式緩存”,但是memcache本身完全不具備分布式的功能,memcache集群之間不會相互通信,所謂的“分布式”,完全依賴于客戶端程序的實現,就像下面這張圖的流程一樣。
同時基于這張圖,理一下memcache一次寫緩存的流程:
① 應用程序輸入需要寫緩存的數據;
② API將key輸入路由算法模塊,路由算法根據key和memcache集群服務器列表得到一臺服務器編號;
③ 由服務器編號得到memcache及其的ip地址和端口號;
④ API調用通信模塊和指定編號的服務器通信,將數據寫入該服務器,完成一次分布式緩存的寫操作。
讀操作和寫緩存一樣,只要使用相同的路由算法和服務器列表,只要應用程序查詢的是相同的key,memcache客戶端總是訪問相同的客戶端去讀取數據,只要服務器中還緩存著該數據,就能保證緩存命中。
這種memcache集群的方式也是從分區容錯性的方面考慮的,假如node02宕機了,那么node02上面存儲的數據都不可用了,此時由于集群中node0和node1還存在,下一次請求node02中存儲的key值的時候,肯定是沒有命中的,這時先從數據庫中拿到要緩存的數據,然后路由算法模板根據key值在node0和node1中選取一個節點,把對應的數據放進去,這樣下一次就有可以走緩存了。但集群的做法要考慮成本的問題。
5,路由算法
從上面的圖中,看出對服務器集群的管理,路由算法至關重要,就和負載均衡算法一樣,路由算法決定著究竟該訪問集群中的哪臺服務器。
1)余數hash算法:
將要存儲的key-vaule數據進行hash運算得到一個值,然后根據memcache的數據進行整除取余。根據余數把數據方放到對應的服務器上,由于hash值的隨機性很大,所以服務器上存放的數據也就比較平衡,一般不會造成大量數據只放在一臺服務器上的情況,但是這樣又出現一個問題,當添加一臺節點的時候,之前的數據就會讀取不到。
解決方案:
(1)在網站訪問量低的時候,技術團隊加班,擴容,重啟服務器
(2)通過模擬請求的方式進行緩存預熱,使服務器中的數據重新分布。
2) 一致性hash算法:
通過一個叫做一致性hash環的數據結果實現key到緩存服務器的hash映射,簡單來說一致性hash將整個hash值的控制組織成一個虛擬的圓環(這個環被稱為一致性hash環)
缺點:當服務器節點太少的時候,容易造成節點數據不均勻。可以選擇采用增加虛擬節點的方式解決。
更重要的是,集群中緩存服務器節點越多,增加/減少節點帶來的影響越小;也就是說隨著集群規模的增大,繼續命中原有緩存數據的概率會越來越大,雖然仍然有小部分數據緩存在服務器中不能被讀到,但是這個比例足夠小,即使訪問數據庫,也不會對數據庫造成致命的負載壓力。
6,memcache實現原理
首先要說明一點,memcache的數據存放在內存中,因此有以下特點:
1)訪問數據的速度比傳統的關系型數據庫要快,因為傳統的關系型數據庫(mysql,oracle)為了保證數據的持久性,數據存放在硬盤中,io操作速度慢。
2)memcache的數據存放在內存中,只要memcache重啟,數據就會丟失。
3)既然memacache的數據存放在內存中,那么勢必受到機器位數的限制,32位機器最多只能使用2GB的內存空間,64位機器可以認為沒有上限。
然后我們來看一下memcache的原理,memcache最重要的是內存如何分配,memcache采用的內存分配方式是固定空間分配,如下圖所示: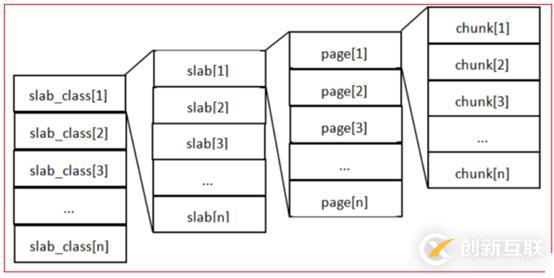
這張圖片里面涉及了 slab_class、 slab、 page、 chunk 四個概念,它們之間的關系是:
1、 MemCache 將內存空間分為一組 slab;
2、每個 slab 下又有若干個 page,每個 page 默認是 1M,如果一個 slab 占用 100M 內存的話,那么這個 slab 下應該有 100 個 page;
3、每個 page 里面包含一組 chunk, chunk 是真正存放數據的地方,同一個 slab 里面的 chunk的大小是固定的;
4、有相同大小 chunk 的 slab 被組織在一起,稱為 slab_class;
MemCache 內存分配的方式稱為 allocator(分配運算), slab 的數量是有限的,幾個、十幾個或者幾十個,這個和啟動參數的配置相關。
memcache中的value存放的地方是有value的大小決定的,value總是會被存放到chunk大小最接近的一個slab中,比如 slab[1]的chunk 大小為 80 字節、 slab[2]的 chunk 大小為 100字節、 slab[3]的 chunk 大小為 128 字節(相鄰 slab 內的 chunk 基本以 1.25 為比例進行增長,MemCache 啟動時可以用-f 指定這個比例),那么過來一個88字節的value,這個value將被放到2號slab中。
放到slab的時候,首先slab要申請內存,申請內存是以page為單位的,所以在放入第一個數據的時候,無論帶下多少,都會有1M大小的page被分配給該slab。申請到page后, slab會將這個page的內存按chunk的大小進行切分,這樣就變成了一個chunk數組,最后從這個 chunk 數組中選擇一個用于存儲數據。
如果這個slab中沒有chunk可以分配了怎么辦,如果memcache啟動沒有追加-M(禁止LRU,這種情況下內存不夠會報Out Of Memory 錯誤),那么 MemCache 會把這個 slab 中最近最少使用的 chunk 中的數據清理掉,然后放上最新的數據。
7,memcache的工作流程

(1)檢查客戶端的請求數據是否在memcached中,如果有,直接把請求數據返回,不在對數據庫進行任何操作,路徑操作為①②③⑦。
(2)如果請求的數據不在memcached中,就去查數據庫,把從數據庫中獲取的數據返回給客戶端,同時把數據緩存一份到memecached中(memcached客戶端不負責,需要程序明確實現),路徑操作為①②④⑤⑦⑥。
(3)每次更新數據庫的同時更新memcached中的數據,保證一致性。
(4)當分配給memcached內存空間用完之后,會使用LRU策略加上到期失效策略,失效數據首先被替換,然后再替換掉最近未使用的數據。
8,memcached的特征
協議簡單:
基于文本協議:常見的協議http,ftp,smtp都是基于文本行的,所謂基于文本行,指的是信息以文本傳遞;
基于libevent事件處理:
libevent是一套利用c語言開發的程序庫,它將BSD系統的kqueue(BSD是unix的衍生版本),linux系統的epoll等事件處理功能封裝成一個接口,與傳統的select相比,提高了性能。
內置的內存管理方式:
所有數據都保存在內存中,數據訪問速度快,但沒有考慮數據單點容災問題,重啟服務,所有數據會丟失。
分布式:
各個memcached服務器之間互不通信,各自獨立存取數據,不共享任何信息,服務器并不具備分布式功能,分布是部署取決于memcache客戶端。
memcache的安裝分為兩個過程:memcache服務器端的安裝和memcached客戶端的安裝。
另外有需要云服務器可以了解下創新互聯cdcxhl.cn,海內外云服務器15元起步,三天無理由+7*72小時售后在線,公司持有idc許可證,提供“云服務器、裸金屬服務器、高防服務器、香港服務器、美國服務器、虛擬主機、免備案服務器”等云主機租用服務以及企業上云的綜合解決方案,具有“安全穩定、簡單易用、服務可用性高、性價比高”等特點與優勢,專為企業上云打造定制,能夠滿足用戶豐富、多元化的應用場景需求。
分享文章:memcache緩存服務器是什么?-創新互聯
標題URL:http://m.kartarina.com/article6/cdchig.html
成都網站建設公司_創新互聯,為您提供外貿建站、靜態網站、網頁設計公司、網站排名、網站建設、用戶體驗
聲明:本網站發布的內容(圖片、視頻和文字)以用戶投稿、用戶轉載內容為主,如果涉及侵權請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網站立場,如需處理請聯系客服。電話:028-86922220;郵箱:631063699@qq.com。內容未經允許不得轉載,或轉載時需注明來源: 創新互聯

- 網站排名與流量之間的關系 2017-02-11
- 網站優化中的404頁面對網站排名有很大影響 2017-01-27
- 處理垃圾外鏈對網站排名影響的方法 2020-02-03
- 優化時如何才能讓您的網站排名靠前 2020-08-06
- 網站優化細節決定網站排名 2021-11-11
- 如何闖過優化關卡才能提升網站排名 2022-09-30
- 棗莊網站排名解開網站被秒收的神秘面紗,還原不變要害詞排名的法門 2023-02-05
- 抓住四個時期助力網站排名增長 2023-02-12
- 怎樣讓網站排名迅速到頁 2022-07-16
- 網站收錄等于網站排名嗎?原因是什么? 2021-11-01
- 怎么處理網站訪問量上升但ALEXA網站排名下降問題 2013-10-09
- 成都網站怎樣做好網站SEO優化,怎樣才能提高網站排名 2023-04-09