GlidedSky字體加密的方法是什么
本篇內容介紹了“GlidedSky字體加密的方法是什么”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
成都創新互聯公司是一家專業提供通遼企業網站建設,專注與網站設計制作、成都網站設計、H5高端網站建設、小程序制作等業務。10年已為通遼眾多企業、政府機構等服務。創新互聯專業網站建設公司優惠進行中。
字體加密: 字體文件的本質是,給定字符、字號等參數,輸出一組像素點信息,用于在設備上展示。
特別簡單一點來說,就是網頁上顯示數據和你真實獲取到的數據,通過某一種關系表連接起來。這樣就可以達到 1 是 2, 3 是 7 的效果。我說的都是比較淺顯的理解,可以去百度或者 Google 一下。我截個圖理解一下。
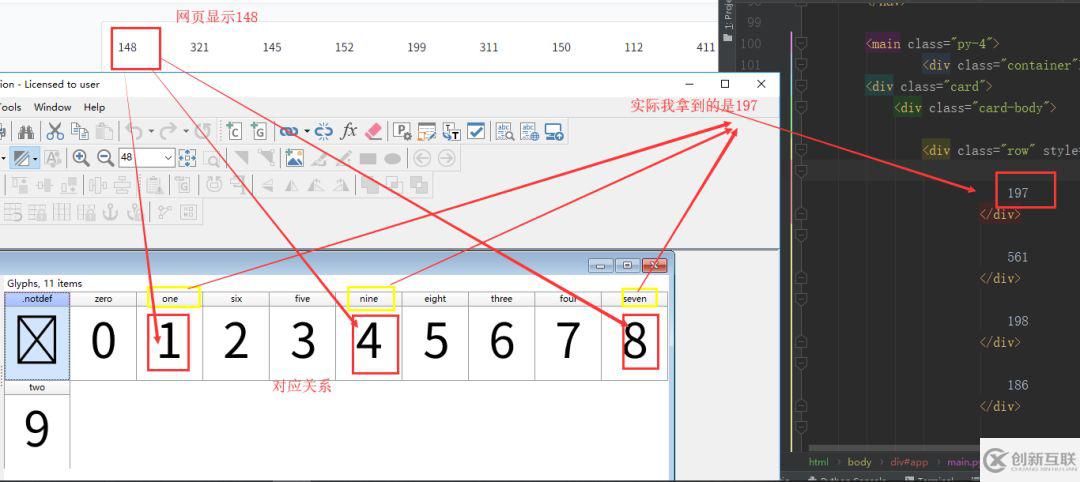
上面的圖應該可以幫助你理解一下。當然這是簡單的字體加密。
而現在我們需要拿真實的響應數據,根據對應關系,去匹配頁面上你所看到的數據。
其實這個對應關系也就是字體文件,需要找到這個字體文件。
第一步:打開網站,打開 network
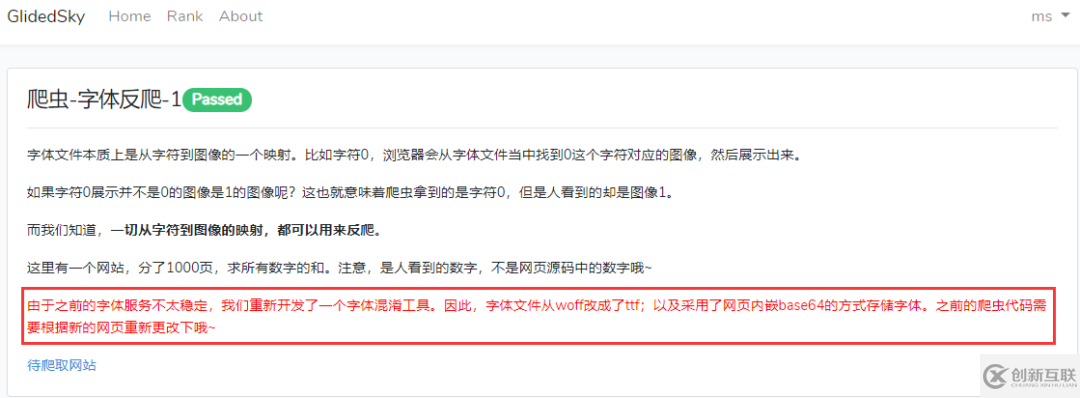
打開網頁你會看到,你看到的和你拿到的數據并不是一致,所以有時候眼睛看到的也不一定是真的。
而且當你刷新頁面的時候,你拿到的數據和上一次也不一樣,說明字體文件更新了。所以最好把這 1000 頁的 HTML 內容保存下來,方便理解。
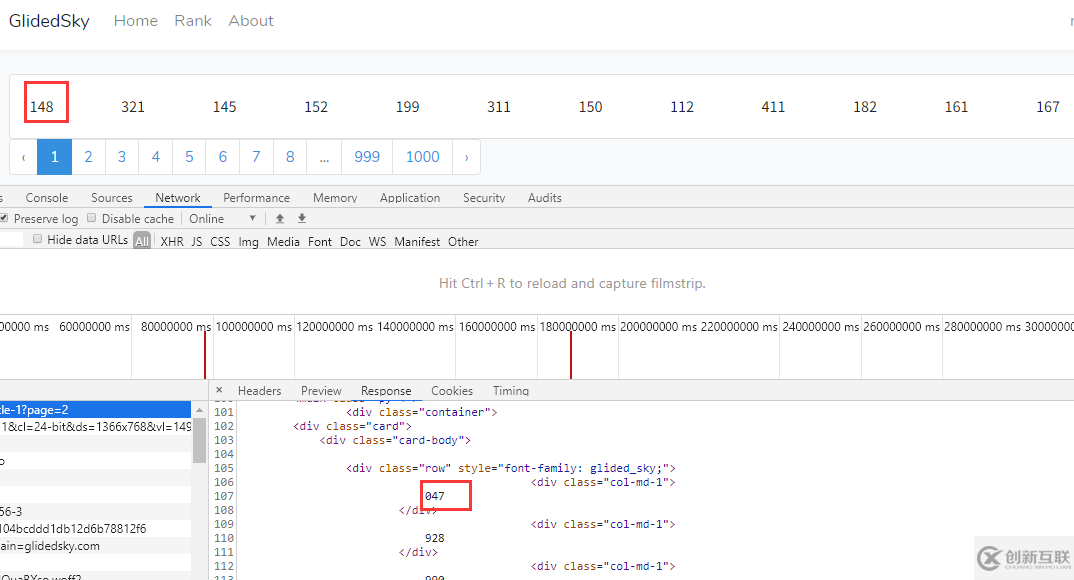
找到字體文件:
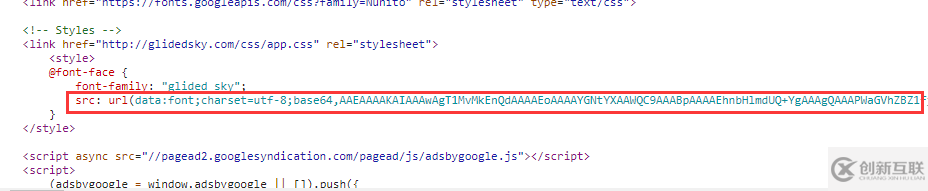
第二步:就是處理這個字體加密
拿到的是 base64 加密的數據,上面的圖圈起來的 base64 后面的,不要把前面的內容也搞出來,解密后保存為 ttf 文件。
至于怎么獲取這 1000 頁的內容,看你自己
直接上代碼:
1 、獲取頁面的 base64 加密的字體文件。使用的庫
import requestsfrom lxml import etreeimport toolsimport base64from fontTools.ttLib import TTFont # 字體解析庫import xml.dom.minidomfrom bs4 import BeautifulSoup
f = open(f'page/font-puzzle-{i}.html').read()soup = BeautifulSoup(f, "html.parser")html = str(soup.select('style'))str_base64 = html.split('base64,', 1)[1]font_face_base64 = str_base64.split(') format', 1)[0]# base64 解密b = base64.b64decode(font_face_base64)# 保存為 ttf 格式的文件with open('ttfji/{}.ttf'.format(i), 'wb') as f:f.write(b)font = TTFont('ttfji/{}.ttf'.format(i))# 轉為 xml 格式文件,并保存font.saveXML('dictxml/{}.xml'.format(i))
可以使用工具 FontCreator 打開,給大家百度網盤的鏈接:
鏈接: https://pan.baidu.com/s/1xzdNQeOUX7JHACpG3CJb_A 提取碼: ebcq 復制這段內容后打開百度網盤手機App,操作更方便哦
打開就是這樣:
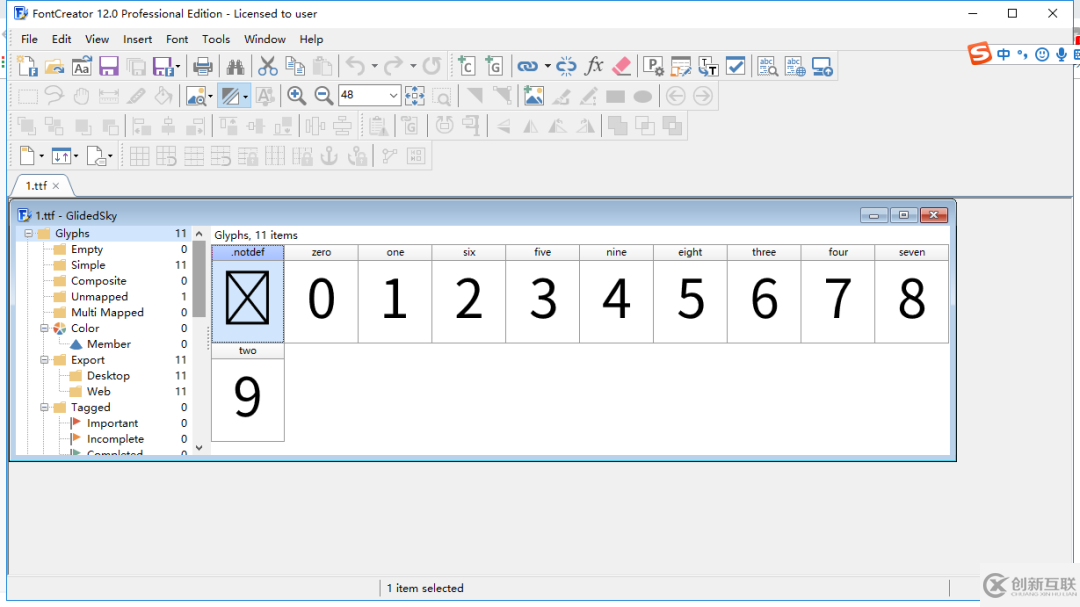
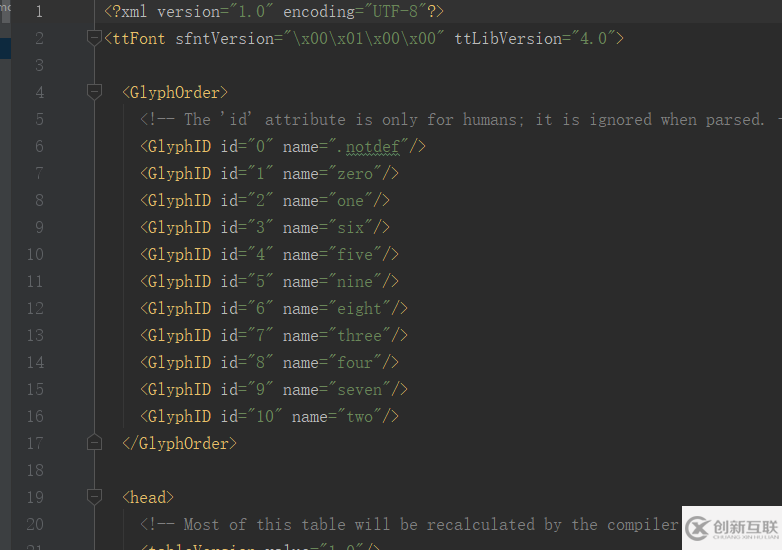
而 xml 文件中是這樣:其實是沒有 10 的,name 向上對應就是你打開 ttf 看到的。GlyphOrder 中顯示的就是對應關系。
而 name 的值代表的數字,就是自己個翻譯過來的數字。可以看看 cmap.
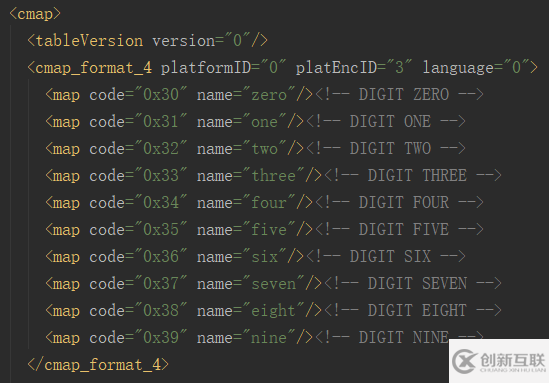
也就是這樣:該字體加密恰巧數字對應它自己的英文名。每一個字體加密都需要去找 name 對應的 value .
dict = { 'zero': '0', 'one': '1', 'two': '2', 'three': '3', 'four': '4', 'five': '5', 'six': '6', 'seven': '7', 'eight': '8', 'nine': '9', } 到這里基本就理解完了,剩下的就是怎么獲取 xml 中的對應關系,就是寫代碼了。理解了寫代碼就容易多了。
newdict = {}dom = xml.dom.minidom.parse('dictxml/{}.xml'.format(i))root = dom.documentElementbb = root.getElementsByTagName('GlyphID')for j in range(1, 11): # 下標從 1 開始,獲取的是zero, k = bb[j].getAttribute("name") # 在字體文件 xml 中對應關系就是 j-1, 也就是0, zero對應的就是0,注釋僅針對第一個字體文件 # 建立對應關系,取出真實的 name 對應的數字。 newdict[dict[k]] = str(j - 1) “GlidedSky字體加密的方法是什么”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注創新互聯網站,小編將為大家輸出更多高質量的實用文章!
分享題目:GlidedSky字體加密的方法是什么
鏈接地址:http://m.kartarina.com/article42/jedhhc.html
成都網站建設公司_創新互聯,為您提供App開發、軟件開發、網頁設計公司、網站排名、電子商務、外貿建站
聲明:本網站發布的內容(圖片、視頻和文字)以用戶投稿、用戶轉載內容為主,如果涉及侵權請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網站立場,如需處理請聯系客服。電話:028-86922220;郵箱:631063699@qq.com。內容未經允許不得轉載,或轉載時需注明來源: 創新互聯

- 企業為什么要找上海網站建設公司和上海網站設計公司網站 2020-11-08
- 建設您企業網站,如何評估網站設計公司的質量? 2019-06-10
- 上海網站建設公司、上海網站設計公司的網站應用開發 2020-11-04
- 網站設計公司通過先進的技術提供服務 2016-09-13
- 上海網站設計公司、上海網站建設公司為阿里巴巴創造了那些不可估量的價值 2020-11-06
- 上海網站設計公司盡力把網站做的更好 2020-11-10
- 上海網站設計公司UI設計和前端開發有哪些區別 2020-11-13
- 網站設計公司如何解決企業的業務需求 2016-09-17
- 上海網站設計公司、上海網站建設公司和微信建設有什么必然的聯系 2020-11-06
- 專業網站設計公司需要遵循的原則規范! 2022-11-04
- 上海網站建設公司,上海網站設計公司制作網站的重點 2020-11-05
- 深圳南山網站建設公司談找網站設計公司的重要性 2022-06-18