c++介紹與入門基礎(詳細總結)-創新互聯
? 關于學c++有一個很有意思的段子,網傳學c++只需要21天即可,前面10天學了c++基礎,然后到21天還在學習對象,接口,多態。然后學著學著就兩年了,兩年后開始可以大量編寫代碼,然后與相關程序員侃侃而談。學到10年后,開始研究物理理論。20年后開始研究生物學了。40年后,運用全部知識編程序制作了一個時空穿梭機。然后跑回到40年前,把做出21天學c++這個決定的自己殺了。
成都創新互聯公司成立于2013年,是專業互聯網技術服務公司,擁有項目網站制作、網站建設網站策劃,項目實施與項目整合能力。我們以讓每一個夢想脫穎而出為使命,1280元汨羅做網站,已為上家服務,為汨羅各地企業和個人服務,聯系電話:18980820575當然這個僅僅是個玩笑,但是側面也反應出學習c++不是一時半會的。有的大佬的也將學習c++分成4個層次。第一個層次,C++基礎(平平常常),。第二個層次,正確高效的使用C++ (駕輕就熟)。第三個層次,深入解讀C++ (出神入化)。第四個層次,研究C++ (返璞歸真)。它相對許多語言復雜,而且難學難精,雖然學習C++有難度,但也是相當有趣且有滿足感的。
這時候有人開始對自己選擇開始懷疑了,認為生命如此短暫,掌握技藝卻要如此長久。同時我們身邊也有很多販賣焦慮的,周圍充斥著程序員生命周期短暫的煙霧彈--30歲后就面臨這失業。其實不然,通過程浩大佬,看到文章《Is Programming Knowledge Related To Age?》這篇論文介紹到了關于年齡的看法,程浩大佬認為(1)程序員技術能力上升是可以到50歲或60歲的。(2)老程序員在獲取新技術上的能力并不比年輕的程序員差。充滿焦慮,急于求成的人只是想呆在井底思維封閉而且想走捷徑速成。這篇文獻給與我一樣正在學習,并且準備為技術和編程執著和堅持的人。因為對所做的事情的理解越深,你就會做的越好。
目錄
前言
c++的發展史?
c++的版本
c++在的工作領域
操作系統以及大型系統軟件開發
服務器端開發 ?
游戲開發
嵌入式和物聯網領域
數字圖像處理
人工智能
分布式應用
C++關鍵字
命名空間
實際工程應用中:?
命名空間的作用:
命名空間需求展示
命名空間定義
命名空間使用
C++輸入&輸出
c++的《hello world》
輸入&輸出說明:
輸入&輸出展示?????
std命名空間的使用慣例
缺省參數?
缺省參數概念
缺省參數分類
函數重載
函數重載概念?
C++支持函數重載的原理--名字修飾(name Mangling)
引用
引用概念
引用特性
常引用
使用場景?
傳值、傳引用效率比較
值和引用的作為返回值類型的性能比較?
引用和指針的區別?
c++的發展史?
? 1925年1月1日,當時AT&T總裁,華特·基佛德(Walter Gifford)收購了西方電子公司的研究部門,成立一個叫做“貝爾電話實驗室公司”的獨立實體,后改稱貝爾實驗室。
當時美國貝爾實驗室是晶體管、激光器、太陽能電池、發光二極管、數字交換機、通信衛星、電子數字計算機、C語言、UNIX操作系統、蜂窩移動通信設備等通信方向,自1925年以來,貝爾實驗室共獲得兩萬五千多項專利,現在,平均每個工作日獲得三項多專利。
隨著科技的創新,丹尼斯里奇所寫的c語言已經不能滿足程序員的需求,因為C語言是結構化和模塊化的語言,適合處理較小規模的程序。對于復雜的問題,規模較大的程序,需要高度的抽象和建模時,C語言則不合適。為了解決軟件危機, 20世紀80年代, 計算機 界提出了OOP(object oriented programming:面向對象)思想,支持面向對象的程序設計語言 應運而生。
c語言之父--丹尼斯里奇的照片

1979年,當時Bjarne Stroustrup正在準備他的博士畢業論文,他有機會使用一種叫做Simula 的語言。顧名思義,Simula語言的主要作用是仿真。Simula67是Simula語言的一種變種,被公認是首款支持面向對象的語言。Stroustrup發現面向對象的思想對于軟件開發非常有用,但是因Simula語言執行效率低,其實用性不強。
不久之后,Stroustrup開始著手“C with Classes”的研發工作,“C with Classes”表明這種新語言是在C基礎上研發的,是C語言的超集。C語言以其高可移植性而廣受好評,且程序執行速度以及底層函數的性能不受程序移植的影響,Stroustrup要做的就是將面向對象的思想引入C語言。新語言的初始版本除了包括C語言的基本特征之外,還具備類、簡單繼承、內聯機制、函數默認參數以及強類型檢查等特性。
1982年,本賈尼·斯特勞斯特盧普(Bjarne Stroustrup)博士在C語言的基礎上引入并擴充了面向對象的概念,發明了一 種新的程序語言。為了表達該語言與C語言的淵源關系,命名為C++。因此:C++是基于C語言而 產生的,它既可以進行C語言的過程化程序設計,又可以進行以抽象數據類型為特點的基于對象的程序設計,還可以進行面向對象的程序設計。
c++之父--本賈尼·斯特勞斯特盧普的照片? ? ? ? ? ??

| 階段 | 內容 |
|---|---|
| C with classes | 類及派生類、公有和私有成員、類的構造和析構、友元、內聯函數、賦值運算符 重載等 |
| C++1.0 | 添加虛函數概念,函數和運算符重載,引用、常量等 |
| C++2.0 | 更加完善支持面向對象,新增保護成員、多重繼承、對象的初始化、抽象類、靜 態成員以及const成員函數 |
| C++3.0 | 進一步完善,引入模板,解決多重繼承產生的二義性問題和相應構造和析構的處 理 |
| C++98 | C++標準第一個版本,絕大多數編譯器都支持,得到了國際標準化組織(ISO)和美 國標準化協會認可,以模板方式重寫C++標準庫,引入了STL(標準模板庫) |
| C++03 | C++標準第二個版本,語言特性無大改變,主要:修訂錯誤、減少多異性 |
| C++05 | C++標準委員會發布了一份計數報告(Technical Report,TR1),正式更名 C++0x,即:計劃在本世紀第一個10年的某個時間發布 |
| C++11 | 增加了許多特性,使得C++更像一種新語言,比如:正則表達式、基于范圍for循 環、auto關鍵字、新容器、列表初始化、標準線程庫等 |
| C++14 | 對C++11的擴展,主要是修復C++11中漏洞以及改進,比如:泛型的lambda表 達式,auto的返回值類型推導,二進制字面常量等 |
| C++17 | 在C++11上做了一些小幅改進,增加了19個新特性,比如:static_assert()的文 本信息可選,Fold表達式用于可變的模板,if和switch語句中的初始化器等 |
| C++20 | 自C++11以來大的發行版,引入了許多新的特性,比如:模塊(Modules)、協 程(Coroutines)、范圍(Ranges)、概念(Constraints)等重大特性,還有對已有 特性的更新:比如Lambda支持模板、范圍for支持初始化等 |
| C++23 | 制定ing |
通過上述不同版本,我們發現其實c++在更新迭代是非常慢的,而且多次更新的改進也不是很大,所以先好多公司主流使用的還是c++98和c++11。好多都是這么形容c++的,好比修房子,他基礎搭建的非常好,但是向上修建的時候就比較偷工減料了,房子上層也越修越窄。
好比迪拜--哈利法塔
現在大家對c++23版本也持有較大期待,因為會迎來許多程序員夢寐以求的標準網絡庫。c++23版本離我們快要到了,有些許朋友會感到才學其他版本就要被遺棄了。不必擔憂,出來之后還沒有穩定,大公司還需要測試之后才能廣泛使用,所以真正到使用其實還有很久。
c++在的工作領域 操作系統以及大型系統軟件開發所有操作系統幾乎都是C/C++寫的,許多大型軟件背后幾乎都是C++寫的,比如:
Photoshop、O?ce、JVM(Java虛擬機)等,究其原因還是性能高,可以直接操控硬件。
服務器端開發 ?后臺開發:主要側重于業務邏輯的處理,即對于前端請求后端給出對應的響應,現在主流采 用java,但內卷化比較嚴重,大廠可能會有C++后臺開發,主要做一些基礎組件,中間件、 緩存、分布式存儲等。服務器端開發比后臺開發跟廣泛,包含后臺開發,一般對實時性要求 比較高的,比如游戲服務器、流媒體服務器、網絡通訊等都采用C++開發的。
游戲開發PC平臺幾乎所有的游戲都是C++寫的,比如:魔獸世界、傳奇、CS、跑跑卡丁車等,市面上 相當多的游戲引擎都是基于C++開發的,比如:Cocos2d、虛幻4、DirectX等。三維游戲領 域計算量非常龐大,底層的數學全都是矩陣變換,想要畫面精美、內容豐富、游戲實時性 搞,這些高難度需求無疑只能選C++語言。比較知名廠商:騰訊、網易、完美世界、巨人網 絡等。
嵌入式和物聯網領域嵌入式:就是把具有計算能力的主控板嵌入到機器裝置或者電子裝置的內部,能夠控制這些 裝置。比如:智能手環、攝像頭、掃地機器人、智能音響等。 談到嵌入式開發,大家最能想到的就是單片機開發(即在8位、16位或者32位單片機產品或者 裸機上進行的開發),嵌入式開發除了單片機開發以外,還包含在soc片上、系統層面、驅動 層面以及應用、中間件層面的開發。 常見的崗位有:嵌入式開發工程師、驅動開發工程師、系統開發工程師、Linux開發工程 師、固件開發工程師等。 知名的一些廠商,比如:以華為、vivo、oppo、小米為代表的手機廠;以紫光展銳、樂鑫為 代表的芯片廠;以大疆、海康威視、大華、CVTE等具有自己終端業務廠商;以及海爾、海 信、格力等傳統家電行業。 隨著5G的普及,物聯網(即萬物互聯,)也成為了一種新興勢力,比如:阿里lot、騰訊lot、京 東、百度、美團等都有硬件相關的事業部。
數字圖像處理數字圖像處理中涉及到大量數學矩陣方面的運算,對CPU算力要求比較高,主要的圖像處理 算法庫和開源庫等都是C/C++寫的,比如:OpenCV、OpenGL等,大名鼎鼎的Photoshop就是C++寫的。
人工智能一提到人工智能,大家首先想到的就是python,認為學習人工智能就要學習python,這個 是誤區,python中庫比較豐富,使用python可以快速搭建神經網絡、填入參數導入數據就 可以開始訓練模型了。但人工智能背后深度學習算法等核心還是用C++寫的。
分布式應用近年來移動互聯網的興起,各應用數據量業務量不斷攀升;后端架構要不斷提高性能和并發 能力才能應對大信息時代的來臨。在分布式領域,好些分布式框架、文件系統、中間組件等 都是C++開發的。對分布式計算影響極大的Hadoop生態的幾個重量級組件:HDFS、zookeeper、HBase等,也都是基于Google用C++實現的GFS、Chubby、BigTable。包括分 布式計算框架MapReduce也是Google先用C++實現了一套,之后才有開源的java版本。
C++關鍵字C++總計63個關鍵字,C語言32個關鍵字。如果還想回顧一下c語言的關鍵字就可以點擊看看。最開始我只需知道有哪些,后面的用法我們也會專門的仔細講。
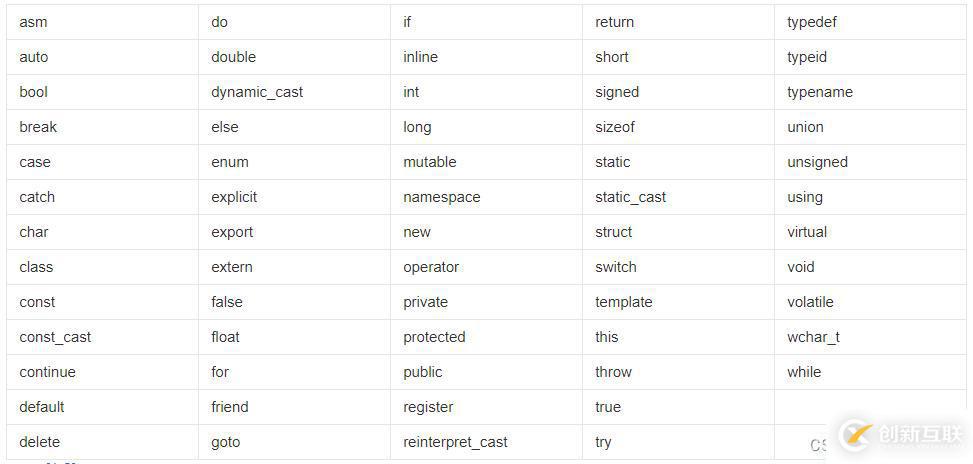
?在編寫大型工程序中,往往是由多個人共同完成的,如果大家命名時想到一起去了就會產生處理程序中常見的同名沖突。還有可能我們使用到的函數庫,因為有些函數我們也不會經常使用,忘記之后也有可能會跟庫函數的命名相同,這樣在程序中就會出現命名沖突(即重復定義)。在C/C++中,變量、函數和后面要學到的類都是大量存在的,這些變量、函數和類的名稱將都存 在于全局作用域中,可能會導致很多沖突。這個時候就會大量使用到命名空間。
命名空間的作用:建立了一些相互分隔的作用域,將一些全局實體分隔開來,以免產生名字沖突。可以根據需要設置多個命名空間,每個命名空間代表一個不同的命名空間域,不同的命名空間不能同名。? ? ??
使用命名空間的目的是對標識符的名稱進行本地化, 以避免命名沖突或名字污染,namespace關鍵字的出現就是針對這種問題的。
命名空間需求展示? 當我們編寫如下代碼,就會出現編譯報錯:error C2365: “rand”: 重定義;以前的定義是“函數” 。這個問題c語言是無法解決的,但是C++提出了namespace來解決 。
#include#includeint rand = 10;
int main()
{
printf("%d\n", rand);
return 0;
} 定義命名空間,需要使用到namespace關鍵字,后面跟命名空間的名字,然后接一對{}即可,{}中即為命名空間的成員。命名空間的名字,一般開發中是用項目名字做命名空間名。
1.正常的命名空間定義
namespace test
{
// 命名空間中可以定義變量/函數/類型
int rand = 10;
int Add(int left, int right)
{
return left + right;
}
struct Node
{
struct Node* next;
int val;
};
}2.命名空間可以嵌套
namespace test1
{
int rand = 10;
int Add(int left, int right)
{
return left + right;
}
struct Node
{
struct Node* next;
int val;
};
namespace test2
{
int a;
int b;
int Sub(int left, int right)
{
return left - right;
}
}
}3.同一個工程中允許存在多個相同名稱的命名空間,編譯器最后會合成同一個命名空間中。
通過預處理后,文件test.h與test.c都將展開。這里用到namespace,它將不同文件的test合成一個test,這里的test就相當于有兩個兩個函數。
test.h文件
namespace test
{
int Sub(int left, int right)
{
return left - right;
}
}test.cpp文件
#define _CRT_SECURE_NO_WARNINGS
#include#include "test.h"
namespace test
{
int Add(int left, int right)
{
return left + right;
}
}
int main()
{
int a = 2;
int b = 3;
int c=test::Add(a, b);
printf("%d", c);
return 0;
} 1.加命名空間名稱及作用域限定符
namespace N
{
int a = 0;
int b = 2;
}
int main()
{
printf("%d",N:: a);
return 0;
}2.使用using將命名空間中某個成員引入
namespace N
{
int a = 0;
int b = 2;
}
using N::b;
int main()
{
printf("%d\n", N::a);
printf("%d\n", b);
return 0;
}3.? 使用using namespace 命名空間名稱引入??
namespace N
{
int a = 0;
int b = 2;
int Add(int left, int right)
{
return left + right;
}
}
using namespce N;
int main()
{
? ?printf("%d\n", N::a);
? ?printf("%d\n", b);
? ?Add(10, 20);
? ?return 0; ? ?
}? 你還記得學習c語言時“printf”的你嗎?還記得你寫下第一個《hello world》的時候嗎?一路學過來c語言全靠它發聲,如果忘記了,那就記下當下c++的親切的問候!
c++的《hello world》#include// std是C++標準庫的命名空間名,C++將標準庫的定義實現都放到這個命名空間中
using namespace std;
int main()
{
cout<<"Hello world!!!"< 輸入&輸出展示?????1.使用cout標準輸出對象(控制臺)和cin標準輸入對象(鍵盤)時,與使用printf與scanf需要包含頭文件
一樣,而這里包含< iostream >頭文件以及按命名空間使用方法使用std。 2.<<是流插入運算符,>>是流提取運算符。 輸出時,選擇流插入運算符;輸入時,選擇流提取運算符。
3.cout和cin是全局的流對象,endl是特殊的C++符號,表示換行輸出,他們都包含在包含< iostream >頭文件中。
4. 使用C++輸入輸出更方便,不需要像printf/scanf輸入輸出時那樣,需要手動控制格式。C++的輸入輸出可以自動識別變量類型。
我們發現運用cin與cout是不需要加輸入輸出類型,那么對于控制浮點的精度問題來怎么解決呢?因為c++是包容c語言的用法的,比如當我們需要控制浮點數輸出精度,控制整形輸出進制格式?,那我們就還是可以選擇用c語言的用法。
#includeusing namespace std;
int main()
{
? int a;
? double b;
? char c;
? ?
? // 可以自動識別變量的類型
? cin>>a;
? cin>>b>>c;
? ?
? cout< 缺省參數? 缺省參數概念1. 在日常練習中,建議直接using namespace std即可,這樣就很方便。
2. using namespace std展開,標準庫就全部暴露出來了,如果我們定義跟庫重名的類型/對 象/函數,就存在沖突問題。該問題在日常練習中很少出現,但是項目開發中代碼較多、規模 大,就很容易出現。所以建議在項目開發中使用,像std::cout這樣使用時指定命名空間 + using std::cout展開常用的庫對象/類型等方式。
? 缺省參數是聲明或定義函數時為函數的參數指定一個默認值 ,在調用該函數時,如果沒有指定實參則采用該默認值,否則使用指定的實參。
#includeusing namespace std;
void Func(int a = 0)
{
cout<< a<< endl;
}
int main()
{
Func(); // 沒有傳參時,使用參數的默認值
Func(10); // 傳參時,使用指定的實參
return 0;
}
說明:
? 使用c語言時,我們是不能給參數進行設置初始值的--語法要求;當我們使用時會出報錯,參數的初始化錯誤。但是在c++中是可以的,相當于直接給函數的參數設置了一個初始值,當調用函數不傳實參時就會得到我們設置的初始值。
缺省參數分類1.全缺省參數
將全部參數設置初始值
#includeusing namespace std;
void Func(int a = 10, int b = 20, int c = 30)
{
cout<< "a = "<< a<< endl;
cout<< "b = "<< b<< endl;
cout<< "c = "<< c<< endl;
}
int main()
{
Func();
Func(100);
Func(100,200);
Func(100,200,300);
return 0;
} 
2.半缺省參數
將一部分參數設置初始值
void Func(int a, int b = 10, int c = 20)
{
cout<< "a = "<< a<< endl;
cout<< "b = "<< b<< endl;
cout<< "c = "<< c<< endl;
}
int main()
{
//Func();//因為第一個參數沒有設置初始值,所以第一個參數需要穿實參
Func(100);
Func(100,200);
Func(100,200,300);
return 0;
}
注意:
1. 半缺省參數必須從右往左依次來給出,不能間隔著給
2. 缺省值必須是常量或者全局變量
3. C語言不支持(編譯器不支持)
4. 缺省參數不能在函數聲明和定義中同時出現
第4點說明
//a.h文件
?void Func(int a = 10);
?
?// a.cpp文件
?void Func(int a = 20)
{}
?
?// 注意:如果生命與定義位置同時出現,恰巧兩個位置提供的值不同,那編譯器就無法確定到底該
用那個缺省值。? 函數重載跟我們生活中一詞多意很像,人們可以通過上下文或者語境來判斷該詞真實的含義,即該詞被重載了。好比如你喜歡的女孩對你說:你很好!或者成為女朋友了對你說:我很好!
函數重載概念?是函數的一種特殊情況,C++允許在同一作用域中聲明幾個功能類似的同名函數,這些同名函數的形參列表(參數個數或類型或類型順序)不同,常用來處理實現功能類似數據類型不同的問題。
1.參數類型不同?
int Add(int left, int right)
{
cout<< "int Add(int left, int right)"<< endl;
return left + right;
}
double Add(double left, double right)
{
cout<< "double Add(double left, double right)"<< endl;
return left + right;
}
int main()
{
Add(10, 20);
Add(10.1, 20.2);
return 0;
}
2、參數個數不同
void f()
{
cout<< "f()"<< endl;
}
void f(int a)
{
cout<< "f(int a)"<< endl;
}
int main()
{
f();
f(10);
return 0;
}
3、參數類型順序不同
void f(int a, char b)
{
cout<< "f(int a,char b)"<< endl;
}
void f(char b, int a)
{
cout<< "f(char b, int a)"<< endl;
}
int main()
{
f(10, 'a');
f('a', 10);
return 0;
}
在這里我們必須知道這幾過程:預處理、編譯、匯編、鏈接。重拾:c--程序環境與預處理。首先我們知道預處理是將各個文件代碼展開,然后把該替換的替換了,該刪除的刪除了。然后進入編譯階段,將c語言代碼轉換成匯編指針,在這過程中有詞法分析,語法分析等。再這就匯編階段,它將匯編代碼轉換為計算機認識的二進制指令,這里重點就是會生成符號表,符號表中有函數名和地址。
下面就是編譯階段,在linux下gcc環境和g++環境編譯完成階段的兩端代碼。
采用C語言編譯器編譯后結果 :
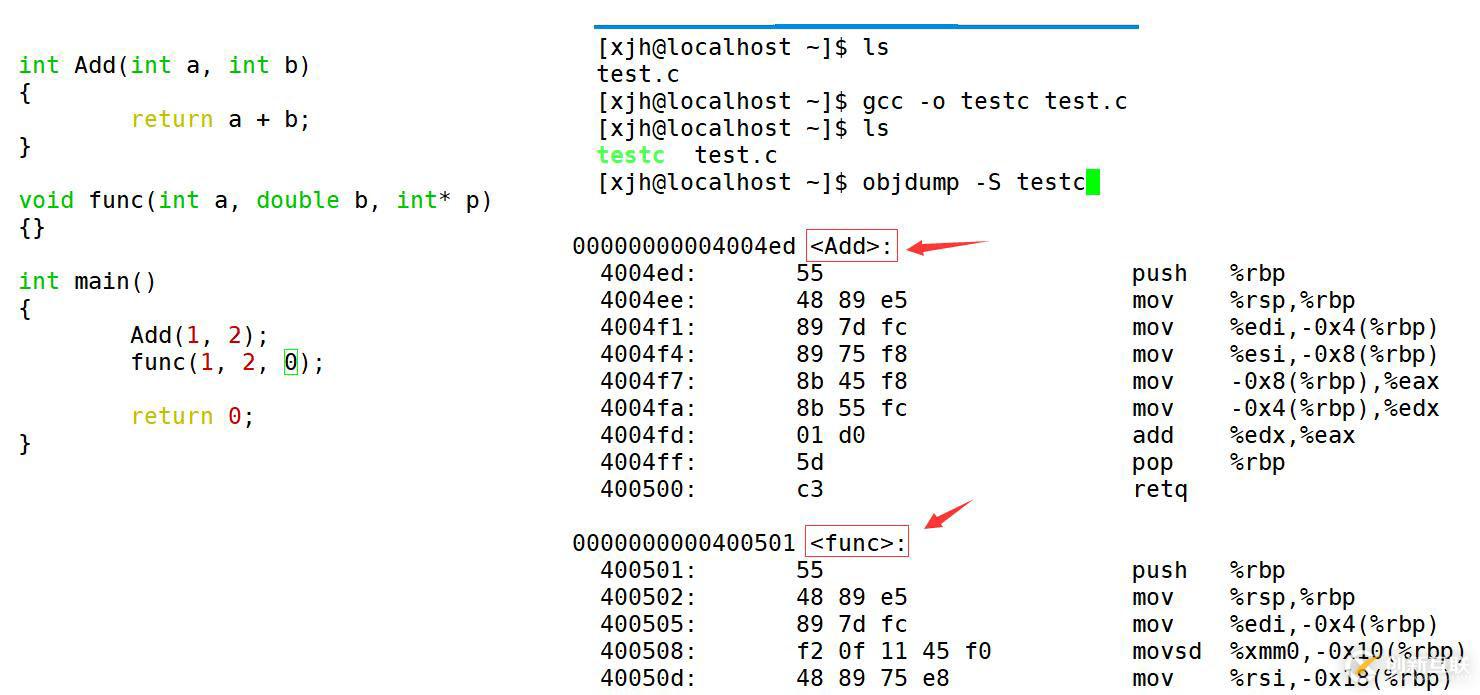
這里我們仔細觀察得到,在linux下,采用gcc編譯完成后,這里的函數名沒有任何修飾,如果我們用兩個相同的函數名,編譯器是無法辨別的。
采用C++編譯器編譯后結果:
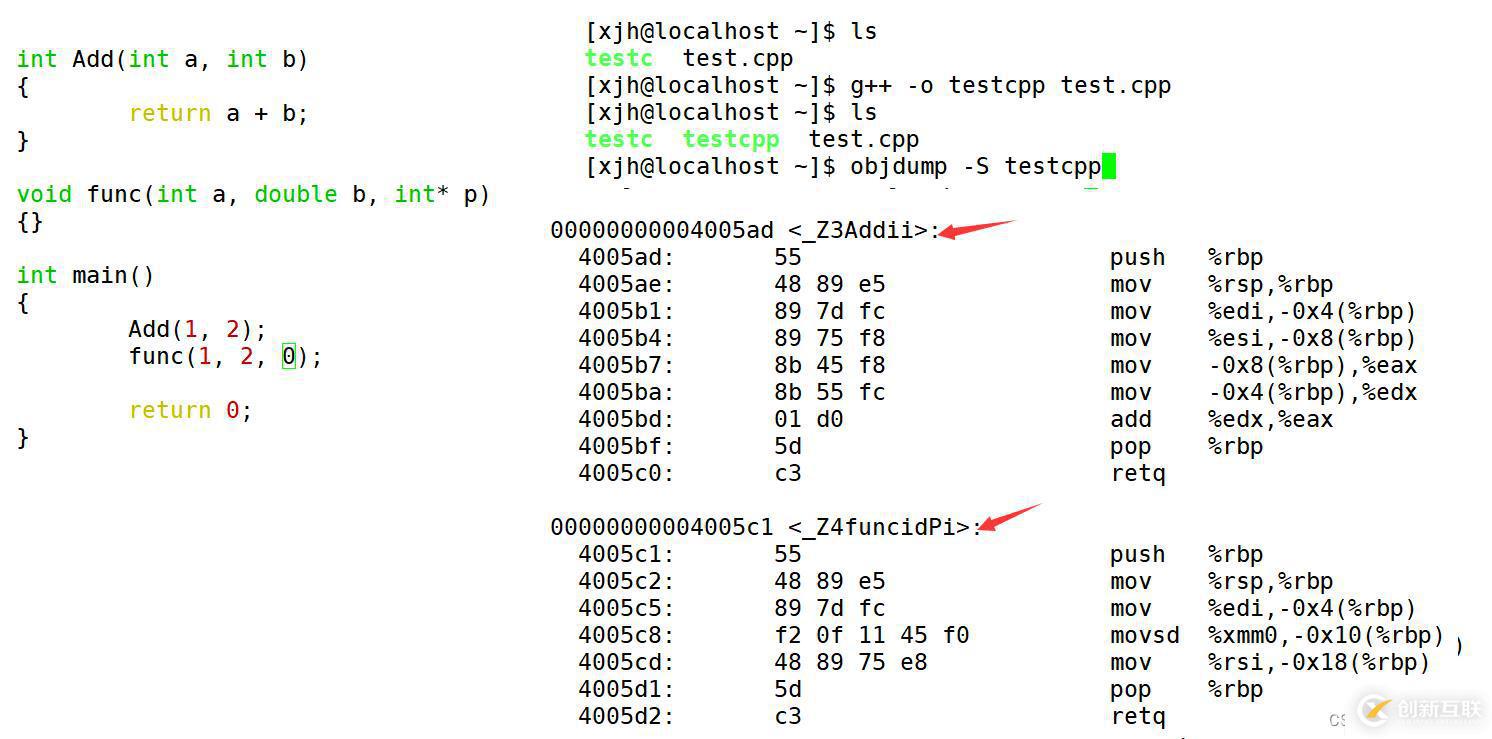
那么在linux下,采用g++編譯完成后,我們發現函數是得到修飾的。編譯器將函數參 數類型信息添加到修改后的名字中。這里好比兩個紅玫瑰蘋果,一個是紅玫瑰125克,一個是紅玫瑰124克。他們都可以裝在一個蘋果籃子里,但是都能取分開。
我們在c++環境下,通過對函數名字的修飾((name Mangling),讓相同的函數不同的功能得以實現。只要參數不同,修飾出來的名字就不一樣,就支持了重載。但是不同系統函數修飾規則是有不同的。
在最后鏈接階段,通過連接器(Linker)將所有二進制形式的目標文件和系統組件組合成一個可執行文件。
引用 引用概念引用不是新定義一個變量,而是給已存在變量取了一個別名,編譯器不會為引用變量開辟內存空 間,它和它引用的變量共用同一塊內存空間。
這里就比好:蔡徐坤,在籃球上粉絲都愛稱:“雞,你太美”。其他方面上,粉絲親切叫一聲:“哥哥或者坤坤”。

類型& 引用變量名(對象名) = 引用實體;
#includevoid TestRef()
{
int a = 10;
int& ra = a;//<====定義引用類型
printf("%p\n", &a);
printf("%p\n", &ra);
}
int main()
{
TestRef();
return 0;
} 注意:引用類型必須和引用實體是同種類型的
引用特性1. 引用在定義時必須初始化
2. 一個變量可以有多個引用
3. 引用一旦引用一個實體,再不能引用其他實體
void TestRef()
{
int a = 10;
// int& ra; ? // (1)該條語句編譯時會出錯
int b = 20;
int& ra = a;
int& ra = b;//(3)報錯:重定義;多次初始化
int& rra = a;
printf("%p %p %p\n", &a, &ra, &rra);
}
int main()
{
TestRef();
return 0;
}const 類型 & 引用名;
作用:是不希望對所引用的內容進行修改。
void TestConstRef()
{
const int a = 10;
//int& ra = a; ? //(1) 該語句編譯時會出錯,a為常量
const int& ra = a;
// int& b = 10; //(2) 該語句編譯時會出錯,b為常量
const int& b = 10;
double d = 12.34;
//int& rd = d; // (3)該語句編譯時會出錯,類型不同
const int& rd = d;
}解釋:
出錯1:
a被const修飾,a的權限被縮小,而這里卻想將a的權限擴大,在操作系統中權限只能縮小,不能被擴大,解決辦法const int& ra=a;
出錯2:
引用的值必須為左值,b為常量。常量是一個真實值,可讀,所以b為右值。那么左值相當于地址。因為這里b是在進行初始化,是一個臨時對象。所以這里錯誤就是右值引用。右值進行引用的時候需要被const修飾,const int& b = 10;
右值引用簡單理解,就是綁定到左值的引用,右值引用的特點是:它將讓其所綁定的右值重獲新生,即使該右值本身是一個臨時變量,但是它本身卻不能綁定任何左值。
錯誤3:
d為double類型,引用不能改變類型。那么這里加const讓rd變成可讀,相當于對d建立臨時變量,以前我們遇到的截斷,提升都屬于通建立臨時變量解決的問題的。
運用:
void func(const int& b)
{
cout<< "b:"<< &b<< endl;
int c = b;
cout<< "c:"<< &c<< endl;
c++;
cout<< "c value"<< c<< endl;
}
int main()
{
int a = 10;
cout<< "a:"<< &a<< endl;
func(a);
return 0;
}
可以看出a和b的地址一樣,而c與b的地址不一樣,可以修改c的值,但是無法修改b的內容。
使用場景?1.做參數
void Swap(int& left, int& right)
{
int temp = left;
left = right;
right = temp;
}
int main()
{
int a = 5, b = 6;
Swap(a,b);
cout<< a<<" "<< b<< endl;
return 0;
}
以前我們學習c語言是用的指針,現在我們學習c++就可以用引用替代,而且書寫代碼更加簡潔。?
2.做返回值
這里引用做返回值使用是就需要特別小心,因為會發生函數棧幀,當函數被銷毀的時候,他原來的空間就會被覆蓋,那么有可能會我們用得到的返回值,再去進行訪問時就找到原來那個值。
列如:
這里使用static,返回值n是靜態變量,存放的空間是在全局區(代碼區)而不是棧區。
int& Count()
{
? static int n = 0;
? n++;
? // ...
? return n;
}那么使用下面代碼會發生什么呢?
int& Add(int a, int b)
{
? ?int c = a + b;
? ?return c;
}
int main()
{
? ?int& ret = Add(1, 2);
? ?Add(3, 4);
? ?cout<< "Add(1, 2) is :"<< ret<
我們發現第二次使用的Add函數時,ret的結果發生了改變。這里主要是因為兩次都是使用的Add函數,開辟的空間是一樣大,所以第一次使用函數的空間被第二次使用函數的空間所覆蓋。原本是3的值,第二次進行訪問的時候原位置是7了。
如果想象不出這個過程,通過圖來理解:
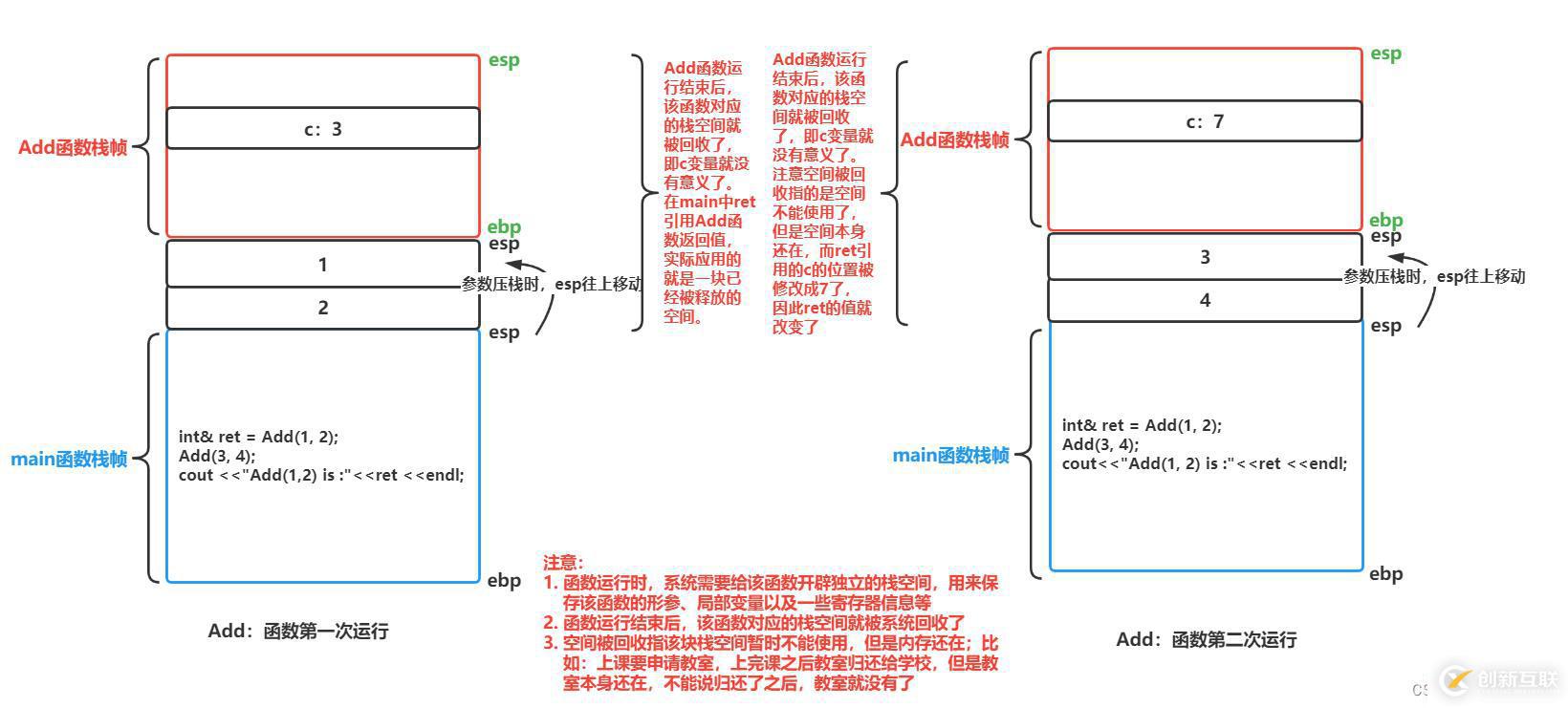
我們這里只是一種情況,其實它有三種情況:(1)原來的值 (2)隨機值 (3)被覆蓋的值
int& Add(int a, int b)
{
int c = a + b;
return c;
}
int main()
{
int& ret = Add(1, 2);
cout<< "Add(1, 2) is :"<< ret<< endl;
cout<< "Add(1, 2) is :"<< ret<< endl;
Add(3, 4);
cout<< "Add(1, 2) is :"<< ret<< endl;
return 0;
}
那么如何理解這三種情況呢?
其實很好理解,因為太貼近我們生活了。當你一個人去開房,走的時候發現你華為手機掉在房間了,然后你回去找,第一種情況:你找到了你自己的手機。第二種情況:阿姨打掃了,原來的地方沒有你的手機,可能放在前臺了。第三中情況:別人已經入住了,你原來放手機的位置放的是蘋果手機(別人的)。
我們要記住這個是錯誤代碼展示,只是讓我們深入理解之后不在編寫出這樣的代碼。
正確代碼:
//方法一
int Add(int a, int b)
{
int c = a + b;
return c;
}
//方法二
int& Add(int a, int b)
{
static int c = a + b;
return c;
}傳值、傳引用效率比較結論:
如果函數返回時,出了函數作用域,如果返回對象還在(還沒還給系統),則可以使用引用返回,如果已經還給系統了,則必須使用傳值返回。
以值作為參數或者返回值類型,在傳參和返回期間,函數不會直接傳遞實參或者將變量本身直接返回,而是傳遞實參或者返回變量的一份臨時的拷貝,因此用值作為參數或者返回值類型,效率是非常低下的,尤其是當參數或者返回值類型非常大時,效率就更低。
#includestruct A{
int a[10000];
};
void TestFunc1(A a){
}
void TestFunc2(A& a){
}
void TestRefAndValue(){
A a; // 以值作為函數參數
size_t begin1 = clock();
for (size_t i = 0; i< 10000; ++i)
TestFunc1(a);
size_t end1 = clock();
// 以引用作為函數參數
size_t begin2 = clock();
for (size_t i = 0; i< 10000; ++i)
TestFunc2(a);
size_t end2 = clock();
// 分別計算兩個函數運行結束后的時間
cout<< "TestFunc1(A)-time:"<< end1 - begin1<< endl;
cout<< "TestFunc2(A&)-time:"<< end2 - begin2<< endl;
}
int main()
{
TestRefAndValue();
return 0;
} 
傳值和指針在作為傳參以及返回值類型上效率相差很大。
#includestruct A{ int a[10000]; };
A a;// 值返回
A TestFunc1() {
return a;
}
// 引用返回
A& TestFunc2(){
return a;
}
void TestReturnByRefOrValue(){
// 以值作為函數的返回值類型
size_t begin1 = clock();
for (size_t i = 0; i< 100000; ++i)
TestFunc1();
size_t end1 = clock();
// 以引用作為函數的返回值類型
size_t begin2 = clock();
for (size_t i = 0; i< 100000; ++i)
TestFunc2();
size_t end2 = clock();
// 計算兩個函數運算完成之后的時間
cout<< "TestFunc1 time:"<< end1 - begin1<< endl;
cout<< "TestFunc2 time:"<< end2 - begin2<< endl;
}
int main()
{
TestReturnByRefOrValue();
return 0;
} 
在語法概念上引用就是一個別名,沒有獨立空間,和其引用實體共用同一塊空間。
int main(){
int a = 10;
int& ra = a;
cout<< "&a = "<< &a<< endl;
cout<< "&ra = "<< &ra<< endl;
return 0;
}
在語法上,他們的地址都是一樣的,所以共用一塊空間。但是在底層實現上實際是有空間的,因為引用是按照指針方式來實現的。
int main(){
int a = 10;
int& ra = a;
ra = 20;
int* pa = &a;
*pa = 20;
return 0;
}引用和指針的語法對比圖:
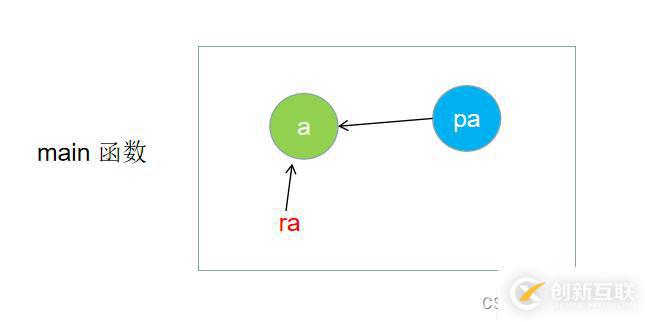
我們來看下引用和指針的匯編代碼對比:

在底層引用與指針,當變量很小的時候都是用寄存器存儲的,相當于開辟一塊臨時變量。?
引用和指針的不同點:
內聯函數1. 引用概念上定義一個變量的別名,指針存儲一個變量地址。
2. 引用在定義時必須初始化,指針沒有要求
3. 引用在初始化時引用一個實體后,就不能再引用其他實體,而指針可以在任何時候指向任何一個同類型實體
4. 沒有NULL引用,但有NULL指針
5. 在sizeof中含義不同:引用結果為引用類型的大小,但指針始終是地址空間所占字節個數(32
位平臺下占4個字節)
6. 引用自加即引用的實體增加1,指針自加即指針向后偏移一個類型的大小
7. 有多級指針,但是沒有多級引用
8. 訪問實體方式不同,指針需要顯式解引用,引用編譯器自己處理
9. 引用比指針使用起來相對更安全
? 在c語言中,我們為了解決調用函數不開辟棧幀,我們經常會使用到宏,但是使用宏是有缺陷的,1不能調試,2沒有類型安全檢查,3容易寫錯。為了解決這些問題c++就使用內聯函數。
宏與內聯的比較#include#define Add(x,y) ((x)+(y))
inline int add(int x, int y)
{
return x + y;
}
int main()
{
int x = 10, y = 20;
int ret = Add(x, y);
int ret2 = add(x, y);
printf("%d\n",ret);
printf("%d\n", ret2);
return 0;
} 以inline修飾的函數叫做內聯函數,編譯時C++編譯器會在調用內聯函數的地方展開,沒有函數調 用建立棧幀的開銷,內聯函數提升程序運行的效率。
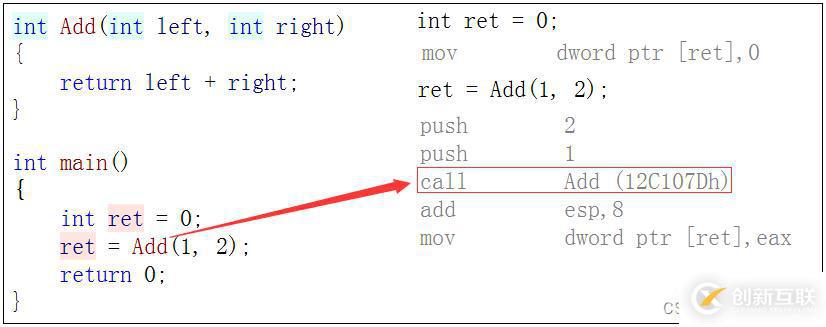
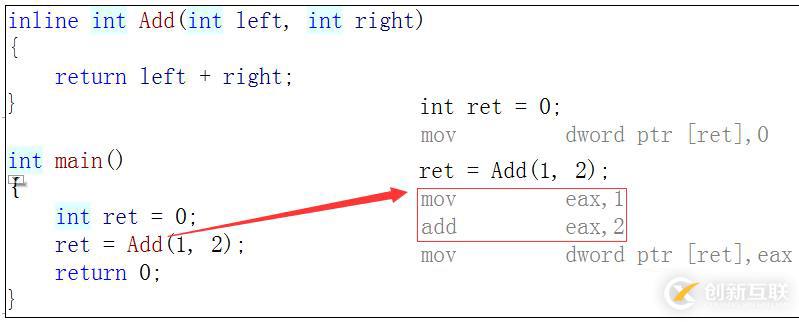
如果在上述函數前增加inline關鍵字將其改成內聯函數,在編譯期間編譯器會用函數體替換函數的 調用。
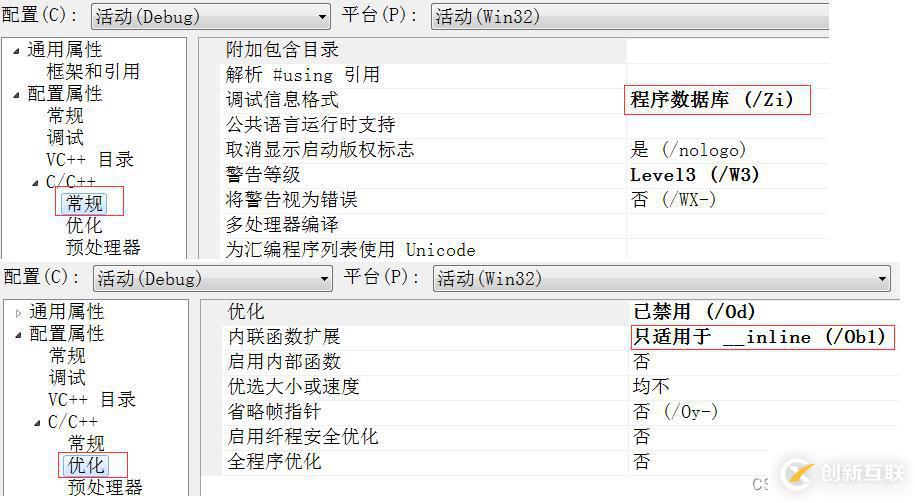
查看方式:?
1. 在release模式下,查看編譯器生成的匯編代碼中是否存在call Add
2. 在debug模式下,需要對編譯器進行設置,否則不會展開(因為debug模式下,編譯器默認不 會對代碼進行優化,以下給出vs2013的設置方式)
 特性
特性1. inline是一種以空間換時間的做法,如果編譯器將函數當成內聯函數處理,在編譯階段,會 用函數體替換函數調用,缺陷:可能會使目標文件變大,優勢:少了調用開銷,提高程序運行效率。
展開會用更多的寄存器,空間就會變大,這樣就會影響可執行程序的大小--安裝包。
2. inline對于編譯器而言只是一個建議,不同編譯器關于inline實現機制可能不同,一般建議:將函數規模較小(即函數不是很長,具體沒有準確的說法,取決于編譯器內部實現)、不是遞歸、且頻繁調用的函數采用inline修飾,否則編譯器會忽略inline特性。
當函數長了之后展開會發聲代碼膨脹
3. inline不建議聲明和定義分離,分離會導致鏈接錯誤。因為inline被展開,就沒有函數地址 了,鏈接就會找不到。 ?
// F.h
#includeusing namespace std;
inline void f(int i);
// F.cpp
#include "F.h"
void f(int i)
{
cout<< i<< endl;
}
// main.cpp
#include "F.h"
int main()
{
f(10);
return 0;
}
// 鏈接錯誤:main.obj : error LNK2019: 無法解析的外部符號 "void __cdecl
f(int)" (?f@@YAXH@Z),該符號在函數 _main 中被引用 隨著程序越來越復雜,程序中用到的類型也越來越復雜,經常體現在:
1. 類型難于拼寫
2. 含義不明確導致容易出錯
#include#include std::map::iterator 是一個類型,但是該類型太長了,特別容 易寫錯。聰明的同學可能已經想到:可以通過typedef給類型取別名,比如: ?
#include #include
typedef std::mapstd::string, std::string>Map;
int main() {
Map m{
{
"apple", "蘋果" },{ "orange", "橙子" }, {"pear","梨"}
};使用typedef給類型取別名確實可以簡化代碼,但是typedef有會遇到新的難題: 在編程時,常常需要把表達式的值賦值給變量,這就要求在聲明變量的時候清楚地知道表達式的 類型。然而有時候要做到這點并非那么容易,因此C++11給auto賦予了新的含義。
auto簡介在早期C/C++中auto的含義是:使用auto修飾的變量,是具有自動存儲器的局部變量,但遺憾的 是一直沒有人去使用它,大家可思考下為什么?
C++11中,標準委員會賦予了auto全新的含義即:auto不再是一個存儲類型指示符,而是作為一 個新的類型指示符來指示編譯器,auto聲明的變量必須由編譯器在編譯時期推導而得。
int TestAuto()
{
return 10;
}
int main()
{
int a = 10;
auto b = a;
auto c = 'a';
auto d = TestAuto();
cout<< typeid(b).name()<< endl;
cout<< typeid(c).name()<< endl;
cout<< typeid(d).name()<< endl;
//auto e; 無法通過編譯,使用auto定義變量時必須對其進行初始化
return 0;
}auto的使用細則【注意】
使用auto定義變量時必須對其進行初始化,在編譯階段編譯器需要根據初始化表達式來推導auto的實際類型。因此auto并非是一種“類型”的聲明,而是一個類型聲明時的“占位符”,編譯器在編 譯期會將auto替換為變量實際的類型。
1. auto與指針和引用結合起來使用 用auto聲明指針類型時,用auto和auto*沒有任何區別,但用auto聲明引用類型時則必須 加&
int main()
{
? ?int x = 10;
? ?auto a = &x;
? ?auto* b = &x;
? ?auto& c = x;
? ?cout<< typeid(a).name()<< endl;
? ?cout<< typeid(b).name()<< endl;
? ?cout<< typeid(c).name()<< endl;
? ?*a = 20;
? ?*b = 30;
? ? c = 40;
? ?return 0;
}2. 在同一行定義多個變量 當在同一行聲明多個變量時,這些變量必須是相同的類型,否則編譯器將會報錯,因為編譯 器實際只對第一個類型進行推導,然后用推導出來的類型定義其他變量。 ??
void TestAuto()
{
? ?auto a = 1, b = 2;
? ?auto c = 3, d = 4.0; ?// 該行代碼會編譯失敗,因為c和d的初始化表達式類型不同
}1. auto不能作為函數的參數
// 此處代碼編譯失敗,auto不能作為形參類型,因為編譯器無法對a的實際類型進行推導
void TestAuto(auto a)
{}2. auto不能直接用來聲明數組 ?
void TestAuto()
{
? ?int a[] = {1,2,3};
? ?auto b[] = {4,5,6};
}3. 為了避免與C++98中的auto發生混淆,C++11只保留了auto作為類型指示符的用法
4. auto在實際中最常見的優勢用法就是跟以后會講到的C++11提供的新式for循環,還有
lambda表達式等進行配合使用。
基于范圍的for循環(C++11) 范圍for的語法在C++98中如果要遍歷一個數組,可以按照以下方式進行:
void TestFor()
{
int array[] = { 1, 2, 3, 4, 5 };
for (int i = 0; i< sizeof(array) / sizeof(array[0]); ++i)
? ? array[i] *= 2;
for (int* p = array; p< array + sizeof(array)/ sizeof(array[0]); ++p)
? ? cout<< *p<< endl;
}對于一個有范圍的集合而言,由程序員來說明循環的范圍是多余的,有時候還會容易犯錯誤。因 此C++11中引入了基于范圍的for循環。for循環后的括號由冒號“ :”分為兩部分:第一部分是范 圍內用于迭代的變量,第二部分則表示被迭代的范圍。
void TestFor()
{
int array[] = { 1, 2, 3, 4, 5 };
for(auto& e : array)
? ? e *= 2;
for(auto e : array)
? ? cout<< e<< " ";
return 0;
}范圍for的使用條件?注意:
與普通循環類似,可以用continue來結束本次循環,也可以用break來跳出整個循環。?
1. for循環迭代的范圍必須是確定的 對于數組而言,就是數組中第一個元素和最后一個元素的范圍;對于類而言,應該提供begin和end的方法,begin和end就是for循環迭代的范圍。
注意:以下代碼就有問題,因為for的范圍不確定
void TestFor(int array[])
{
? ?for(auto& e : array)
? ? ? ?cout<< e<2. 迭代的對象要實現++和==的操作。(關于迭代器這個問題,以后會講,現在提一下,沒辦法 講清楚,現在大家了解一下就可以了)
指針空值nullptr(C++11) C++98中的指針空值在良好的C/C++編程習慣中,聲明一個變量時最好給該變量一個合適的初始值,否則可能會出現 不可預料的錯誤,比如未初始化的指針。如果一個指針沒有合法的指向,我們基本都是按照如下 方式對其進行初始化:
void TestPtr()
{
int* p1 = NULL;
int* p2 = 0;
// ……
}NULL實際是一個宏,在傳統的C頭文件(stddef.h)中,可以看到如下代碼: ?
#ifndef NULL
#ifdef __cplusplus
#define NULL ? 0
#else
#define NULL ? ((void *)0)
#endif
#endif可以看到,NULL可能被定義為字面常量0,或者被定義為無類型指針(void*)的常量。不論采取何 種定義,在使用空值的指針時,都不可避免的會遇到一些麻煩,比如:
void f(int)
{
cout<<"f(int)"<注意:
1. 在使用nullptr表示指針空值時,不需要包含頭文件,因為nullptr是C++11作為新關鍵字引入 的。
2. 在C++11中,sizeof(nullptr) 與 sizeof((void*)0)所占的字節數相同。
3. 為了提高代碼的健壯性,在后續表示指針空值時建議最好使用nullptr。
今天的知識到這里就完了,希望該文章能對各位朋友有一絲幫助!? ? ? ? ? ? ? ? ? ? ? ?? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? (全文完)?
?? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? (全文完)?
你是否還在尋找穩定的海外服務器提供商?創新互聯www.cdcxhl.cn海外機房具備T級流量清洗系統配攻擊溯源,準確流量調度確保服務器高可用性,企業級服務器適合批量采購,新人活動首月15元起,快前往官網查看詳情吧
當前名稱:c++介紹與入門基礎(詳細總結)-創新互聯
網站地址:http://m.kartarina.com/article38/cdcjsp.html
成都網站建設公司_創新互聯,為您提供網站維護、響應式網站、外貿網站建設、定制開發、小程序開發、網站排名
聲明:本網站發布的內容(圖片、視頻和文字)以用戶投稿、用戶轉載內容為主,如果涉及侵權請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網站立場,如需處理請聯系客服。電話:028-86922220;郵箱:631063699@qq.com。內容未經允許不得轉載,或轉載時需注明來源: 創新互聯

- 營銷型網站建設需要注意事項 2021-06-14
- 營銷型網站建設關鍵詞的部署技巧 2022-08-06
- 好的營銷型網站建設一定要注重細節 2022-05-02
- 高端營銷型網站建設如何定位 2022-04-28
- 企業營銷型網站建設需要從哪些方面開始 2021-11-24
- 如何改善營銷型網站建設存在的問題? 2022-10-01
- 外貿營銷型網站建設有哪些重點? 2021-09-21
- 營銷型網站建設有什么需要? 2022-06-06
- 營銷型網站建設要用到哪些 2017-08-13
- 營銷型網站建設的技巧有哪些? 2022-12-20
- 營銷型網站建設有哪些地方需要改進? 2022-05-04
- 企業策劃營銷型網站建設的七個要點 2022-05-20